


UTF-8與UTF-8(BOM)區(qū)別和一些說明
導讀
本文詳細介紹了UTF-8編碼中漢字所占字節(jié)數,以及UTF-8與UTF-8BOM的區(qū)別和影響。BOM在UTF-8文件中的存在可能導致PHP解析錯誤和Linux下SQL執(zhí)行報錯。建議使用無BOM的UTF-8編碼,提供了解決BOM問題的Linux和Windows方法。
在我們通常使用的windows系統(tǒng)中,我發(fā)現了一個有趣的現象。我新建一個空的文本文檔,點擊文件-另存為-編碼選擇UTF-8,然后保存。此時這個文件明明是空的,卻占了3字節(jié)大小。原因在于:此時保存的編碼方式自動會變?yōu)閁TF-8 BOM
一、一個漢字在不同的編碼方式中占多少字節(jié)?
1.在UTF-8中,一個漢字占3個字節(jié)(一個字符占一個字節(jié))
2.在ASCII碼中,一個漢字占2個字節(jié)(一個字符占一個字節(jié))
3.在Unicode編碼中,一個漢字占2個字節(jié)(一個字符同樣占兩個字節(jié),所以JAVA中char a = '中';是可以的)
二、UTF-8與UTF-8 BOM
BOM即byte order mark,具體含義可百度百科或維基百科,UTF-8文件中放置BOM主要是微軟的習慣,但是放在別的系統(tǒng)上會出現問題。不含BOM的UTF-8才是標準形式,UTF-8不需要BOM帶BOM的UTF-8文件的開頭會有U+FEFF,所以我新建的空文件會有3字節(jié)的大小。
BOM的含義
BOM即Byte Order Mark字節(jié)序標記。BOM是為UTF-16和UTF-32準備的,用戶標記字節(jié)序(byte order)。拿UTF-16來舉例,其是以兩個字節(jié)為編碼單元,在解釋一個UTF-16文本前,首先要弄清楚每個編碼單元的字節(jié)序。例如收到一個“奎”的Unicode編碼是594E,“乙”的Unicode編碼是4E59。如果我們收到UTF-16字節(jié)流"594E",那么這是“奎”還是“乙”?
Unicode規(guī)范中推薦的標記字節(jié)順序的方法是BOM:在UCS編碼中有一個叫做"ZERO WIDTH NO-BREAK SPACE"(零寬度無間斷空間)的字符,它的編碼是FEFF。而FEFF在UCS中是不不能再的字符(即不可見),所以不應該出現在實際傳輸中。UCS規(guī)范建議我們在傳輸字節(jié)流前,先傳輸字符"ZERO WIDTH NO-BREAK SPACE"。這樣如果接收者接收到FEFF,就表明這個字節(jié)流是Big-Endian的;如果收到FFFE,就表明這個字節(jié)流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被稱為BOM。
UTF-8是以字節(jié)為編碼單元,沒有字節(jié)序的問題。
延伸一下:
UTF-8編碼是以1個字節(jié)為單位進行處理的,不會受CPU大小端的影響;需要考慮下一位時就地址 + 1。
UTF-16、UTF-32是以2個字節(jié)和4個字節(jié)為單位進行處理的,即1次讀取2個字節(jié)或4個字節(jié),這樣一來,在存儲和網絡傳輸時就要考慮1個單位內2個字節(jié)或4個字節(jié)之間順序的問題。
UTF-8 BOM
UTF-8 BOM又叫UTF-8 簽名,UTF-8不需要BOM來表明字節(jié)順序,但可以用BOM來表明編碼方式。當文本程序讀取到以 EF BB BF開頭的字節(jié)流時,就知道這是UTF-8編碼了。Windows就是使用BOM來標記文本文件的編碼方式的。
補充:
"ZERO WIDTH NO-BREAK SPACE"字符的UCS編碼為FEFF(假設為大端),對應的UTF-8編碼為 EF BB BF
即以EF BB BF開頭的字節(jié)流可表明這是段UTF-8編碼的字節(jié)流。但如果文件本身就是UTF-8編碼的,EF BB BF這三個字節(jié)就毫無用處了。 所以,可以說BOM的存在對于UTF-8本身沒有任何作用。
UTF-8文件中包含BOM的壞處
1、對php的影響
php在設計時就沒有考慮BOM的問題,也就是說他不會忽略UTF-8編碼的文件開頭的那三個EF BB BF字符,直接當做文本進行解析,導致解析錯誤。
2、在linux上執(zhí)行SQL腳本報錯
最近開發(fā)過程中遇到,windows下編寫的SQL文件,在linux下執(zhí)行時,總是報錯。
在文件的開頭,無論是使用中文注釋還是英文注釋,甚至去掉注釋,也會報SP2-0734: unknown command beginning "?<span "="">dec<span "="">lare ..." - rest of line ignored. 的錯誤。
<span "="">如下是文件開頭部分
1 --create tablespace
2 declare
3 v_tbs_name varchar2(200):='hytpdtsmsshistorydb';
4 begin
報錯如下:
1 SP2-0734: unknown command beginning "?--create ..." - rest of line ignored.
2
3
4 PL/SQL procedure successfully completed.
網上沒有找到類似問題的解決辦法,且文件編碼確認已經更改為utf-8,該問題困惑了我很久。
最后查看一下BOM與 no BOM的區(qū)別,嘗試更改為no BOM,居然就沒有再出現錯誤。
修改完成后,無論使用中文,還是英文,或者去掉注釋,都能正常執(zhí)行。
血淚建議:UTF-8最好不要帶BOM
UTF-8」和「帶 BOM 的 UTF-8」的區(qū)別就是有沒有 BOM。即文件開頭有沒有 U+FEFF。
1、Linux中查看BOM的方法:使用less命令,其它命令可能看不到效果:

發(fā)現詞語之前多了一個<U+FEFF>。
三、創(chuàng)建UTF-8(而非UTF-8 BOM)文件的方法
在發(fā)現文件另存為UTF-8缺得到UTF-8 BOM文件后,我們怎樣才能得到UTF-8呢?
方法:.先另存為UTF-8保存,再使用notepad++打開,把里面的編碼設置為無BOM的UTF-8然后保存。(此方法治標不治本,因為當你再次在里面寫漢字時,文件會自動變成UTF-8 BOM)
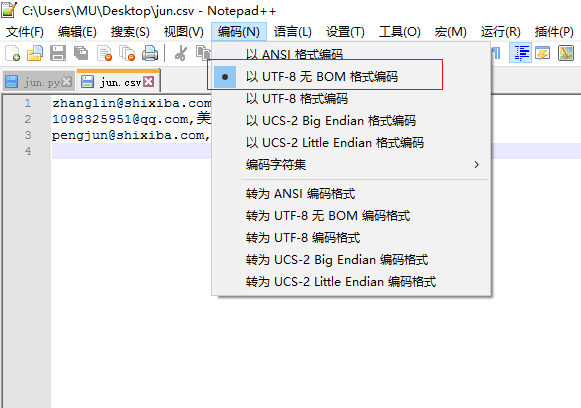
2、UTF-8去除BOM的方法
Linux下:
(1)
1)vim打開文件
2)執(zhí)行:set nobomb
3)保存:wq
(2)
dos2unix filename
將windows格式文件轉為Unix、Linux格式文件。該命令不僅可將windows文件的換行符\r\n轉為Unix、Linux文件的換行符\n,還可以將UTF-8 Unicode (with BOM)轉換為UTF-8 Unicode.
PS:
遇到一個比較坑爹的情況,1個UTF-8 Unicode (with BOM)文件中包含兩個<U+FEFF>,這是無論使用方法(1)還是方法(2),都要執(zhí)行兩次才能將<U+FEFF>完全去除!!!
(2)Windows下,使用NotePad++打開這個文件,然后選擇“編碼”,再選擇“以UTF-8無BOM格式編碼”,最后重新保存文件即可!
原文鏈接:https://blog.csdn.net/weixin_50464560/article/details/119277677
