十步優(yōu)化SQL Server中的數(shù)據(jù)訪問
當前位置:點晴教程→知識管理交流
→『 技術(shù)文檔交流 』
故事開篇:你和你的團隊經(jīng)過不懈努力,終于使網(wǎng)站成功上線,剛開始時,注冊用戶較少,網(wǎng)站性能表現(xiàn)不錯,但隨著注冊用戶的增多,訪問速度開始變慢,一些用戶開始發(fā)來郵件表示抗議,事情變得越來越糟,為了留住用戶,你開始著手調(diào)查訪問變慢的原因。
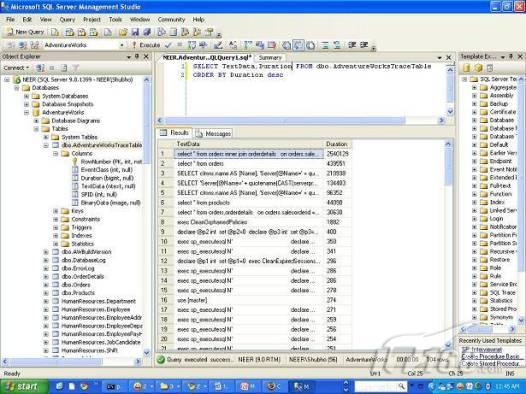
經(jīng)過緊張的調(diào)查,你發(fā)現(xiàn)問題出在數(shù)據(jù)庫上,當應用程序嘗試訪問/更新數(shù)據(jù)時,數(shù)據(jù)庫執(zhí)行得相當慢,再次深入調(diào)查數(shù)據(jù)庫后,你發(fā)現(xiàn)數(shù)據(jù)庫表增長得很大,有些表甚至有上千萬行數(shù)據(jù),測試團隊開始在生產(chǎn)數(shù)據(jù)庫上測試,發(fā)現(xiàn)訂單提交過程需要花5分鐘時間,但在網(wǎng)站上線前的測試中,提交一次訂單只需要2/3秒。 類似這種故事在世界各個角落每天都會上演,幾乎每個開發(fā)人員在其開發(fā)生涯中都會遇到這種事情,我也曾多次遇到這種情況,因此我希望將我解決這種問題的經(jīng)驗和大家分享。 如果你正身處這種項目,逃避不是辦法,只有勇敢地去面對現(xiàn)實。首先,我認為你的應用程序中一定沒有寫數(shù)據(jù)訪問程序,我將在這個系列的文章中介紹如何編寫最佳的數(shù)據(jù)訪問程序,以及如何優(yōu)化現(xiàn)有的數(shù)據(jù)訪問程序。 范圍 在正式開始之前,有必要澄清一下本系列文章的寫作邊界,我想談的是“事務(wù)性(OLTP)SQL Server數(shù)據(jù)庫中的數(shù)據(jù)訪問性能優(yōu)化”,但文中介紹的這些技巧也可以用于其它數(shù)據(jù)庫平臺。 同時,我介紹的這些技巧主要是面向程序開發(fā)人員的,雖然DBA也是優(yōu)化數(shù)據(jù)庫的一支主要力量,但DBA使用的優(yōu)化方法不在我的討論范圍之內(nèi)。 當一個基于數(shù)據(jù)庫的應用程序運行起來很慢時,90%的可能都是由于數(shù)據(jù)訪問程序的問題,要么是沒有優(yōu)化,要么是沒有按最佳方法編寫代碼,因此你需要審查和優(yōu)化你的數(shù)據(jù)訪問/處理程序。 我將會談到10個步驟來優(yōu)化數(shù)據(jù)訪問程序,先從最基本的索引說起吧! 第一步:應用正確的索引 我之所以先從索引談起是因為采用正確的索引會使生產(chǎn)系統(tǒng)的性能得到質(zhì)的提升,另一個原因是創(chuàng)建或修改索引是在數(shù)據(jù)庫上進行的,不會涉及到修改程序,并可以立即見到成效。 我們還是溫習一下索引的基礎(chǔ)知識吧,我相信你已經(jīng)知道什么是索引了,但我見到很多人都還不是很明白,我先給大家將一個故事吧。 很久以前,在一個古城的的大圖書館中珍藏有成千上萬本書籍,但書架上的書沒有按任何順序擺放,因此每當有人詢問某本書時,圖書管理員只有挨個尋找,每一次都要花費大量的時間。 [這就好比數(shù)據(jù)表沒有主鍵一樣,搜索表中的數(shù)據(jù)時,數(shù)據(jù)庫引擎必須進行全表掃描,效率極其低下。] 更糟的是圖書館的圖書越來越多,圖書管理員的工作變得異常痛苦,有一天來了一個聰明的小伙子,他看到圖書管理員的痛苦工作后,想出了一個辦法,他建議將每本書都編上號,然后按編號放到書架上,如果有人指定了圖書編號,那么圖書管理員很快就可以找到它的位置了。 [給圖書編號就象給表創(chuàng)建主鍵一樣,創(chuàng)建主鍵時,會創(chuàng)建聚集索引樹,表中的所有行會在文件系統(tǒng)上根據(jù)主鍵值進行物理排序,當查詢表中任一行時,數(shù)據(jù)庫首先使用聚集索引樹找到對應的數(shù)據(jù)頁(就象首先找到書架一樣),然后在數(shù)據(jù)頁中根據(jù)主鍵鍵值找到目標行(就象找到書架上的書一樣)。] 于是圖書管理員開始給圖書編號,然后根據(jù)編號將書放到書架上,為此他花了整整一天時間,但最后經(jīng)過測試,他發(fā)現(xiàn)找書的效率大大提高了。 [在一個表上只能創(chuàng)建一個聚集索引,就象書只能按一種規(guī)則擺放一樣。] 但問題并未完全解決,因為很多人記不住書的編號,只記得書的名字,圖書管理員無賴又只有掃描所有的圖書編號挨個尋找,但這次他只花了20分鐘,以前未給圖書編號時要花2-3小時,但與根據(jù)圖書編號查找圖書相比,時間還是太長了,因此他向那個聰明的小伙子求助。 [這就好像你給Product表增加了主鍵ProductID,但除此之外沒有建立其它索引,當使用Product Name進行檢索時,數(shù)據(jù)庫引擎又只要進行全表掃描,逐個尋找了。] 聰明的小伙告訴圖書管理員,之前已經(jīng)創(chuàng)建好了圖書編號,現(xiàn)在只需要再創(chuàng)建一個索引或目錄,將圖書名稱和對應的編號一起存儲起來,但這一次是按圖書名稱進行排序,如果有人想找“Database Management System”一書,你只需要跳到“D”開頭的目錄,然后按照編號就可以找到圖書了。 于是圖書管理員興奮地花了幾個小時創(chuàng)建了一個“圖書名稱”目錄,經(jīng)過測試,現(xiàn)在找一本書的時間縮短到1分鐘了(其中30秒用于從“圖書名稱”目錄中查找編號,另外根據(jù)編號查找圖書用了30秒)。 圖書管理員開始了新的思考,讀者可能還會根據(jù)圖書的其它屬性來找書,如作者,于是他用同樣的辦法為作者也創(chuàng)建了目錄,現(xiàn)在可以根據(jù)圖書編號,書名和作者在1分鐘內(nèi)查找任何圖書了,圖書管理員的工作變得輕松了,故事也到此結(jié)束。 到此,我相信你已經(jīng)完全理解了索引的真正含義。假設(shè)我們有一個Products表,創(chuàng)建了一個聚集索引(根據(jù)表的主鍵自動創(chuàng)建的),我們還需要在ProductName列上創(chuàng)建一個非聚集索引,創(chuàng)建非聚集索引時,數(shù)據(jù)庫引擎會為非聚集索引自動創(chuàng)建一個索引樹(就象故事中的“圖書名稱”目錄一樣),產(chǎn)品名稱會存儲在索引頁中,每個索引頁包括一定范圍的產(chǎn)品名稱和它們對應的主鍵鍵值,當使用產(chǎn)品名稱進行檢索時,數(shù)據(jù)庫引擎首先會根據(jù)產(chǎn)品名稱查找非聚集索引樹查出主鍵鍵值,然后使用主鍵鍵值查找聚集索引樹找到最終的產(chǎn)品。 下圖顯示了一個索引樹的結(jié)構(gòu)  圖 1 索引樹結(jié)構(gòu) 它叫做B+樹(或平衡樹),中間節(jié)點包含值的范圍,指引SQL引擎應該在哪里去查找特定的索引值,葉子節(jié)點包含真正的索引值,如果這是一個聚集索引樹,葉子節(jié)點就是物理數(shù)據(jù)頁,如果這是一個非聚集索引樹,葉子節(jié)點包含索引值和聚集索引鍵(數(shù)據(jù)庫引擎使用它在聚集索引樹中查找對應的行)。 通常,在索引樹中查找目標值,然后跳到真實的行,這個過程是花不了什么時間的,因此索引一般會提高數(shù)據(jù)檢索速度。下面的步驟將有助于你正確應用索引。 確保每個表都有主鍵 這樣可以確保每個表都有聚集索引(表在磁盤上的物理存儲是按照主鍵順序排列的),使用主鍵檢索表中的數(shù)據(jù),或在主鍵字段上進行排序,或在where子句中指定任意范圍的主鍵鍵值時,其速度都是非常快的。 在下面這些列上創(chuàng)建非聚集索引: 1)搜索時經(jīng)常使用到的; 2)用于連接其它表的; 3)用于外鍵字段的; 4)高選中性的; 5)ORDER BY子句使用到的; 6)XML類型。 下面是一個創(chuàng)建索引的例子: CREATE INDEX NCLIX_OrderDetails_ProductID ON dbo.OrderDetails(ProductID) 也可以使用SQL Server管理工作臺在表上創(chuàng)建索引,如圖2所示。 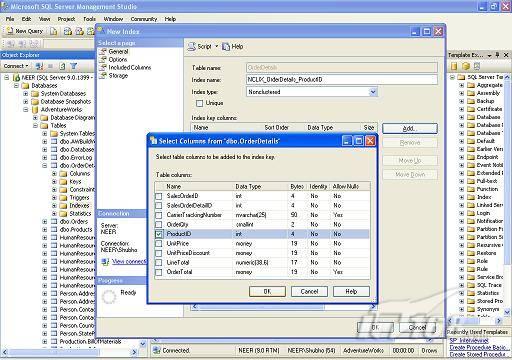 圖 2 使用SQL Server管理工作臺創(chuàng)建索引 第二步:創(chuàng)建適當?shù)母采w索引 假設(shè)你在Sales表(SelesID,SalesDate,SalesPersonID,ProductID,Qty)的外鍵列(ProductID)上創(chuàng)建了一個索引,假設(shè)ProductID列是一個高選中性列,那么任何在where子句中使用索引列(ProductID)的select查詢都會更快,如果在外鍵上沒有創(chuàng)建索引,將會發(fā)生全部掃描,但還有辦法可以進一步提升查詢性能。 假設(shè)Sales表有10,000行記錄,下面的SQL語句選中400行(總行數(shù)的4%): SELECT SalesDate, SalesPersonID FROM Sales WHERE ProductID = 112 我們來看看這條SQL語句在SQL執(zhí)行引擎中是如何執(zhí)行的: 1)Sales表在ProductID列上有一個非聚集索引,因此它查找非聚集索引樹找出ProductID=112的記錄; 2)包含ProductID = 112記錄的索引頁也包括所有的聚集索引鍵(所有的主鍵鍵值,即SalesID); 3)針對每一個主鍵(這里是400),SQL Server引擎查找聚集索引樹找出真實的行在對應頁面中的位置; SQL Server引擎從對應的行查找SalesDate和SalesPersonID列的值。 在上面的步驟中,對ProductID = 112的每個主鍵記錄(這里是400),SQL Server引擎要搜索400次聚集索引樹以檢索查詢中指定的其它列(SalesDate,SalesPersonID)。 如果非聚集索引頁中包括了聚集索引鍵和其它兩列(SalesDate,,SalesPersonID)的值,SQL Server引擎可能不會執(zhí)行上面的第3和4步,直接從非聚集索引樹查找ProductID列速度還會快一些,直接從索引頁讀取這三列的數(shù)值。 幸運的是,有一種方法實現(xiàn)了這個功能,它被稱為“覆蓋索引”,在表列上創(chuàng)建覆蓋索引時,需要指定哪些額外的列值需要和聚集索引鍵值(主鍵)一起存儲在索引頁中。下面是在Sales 表ProductID列上創(chuàng)建覆蓋索引的例子: CREATE INDEX NCLIX_Sales_ProductID--Index name ON dbo.Sales(ProductID)--Column on which index is to be created INCLUDE(SalesDate, SalesPersonID)--Additional column values to include 應該在那些select查詢中常使用到的列上創(chuàng)建覆蓋索引,但覆蓋索引中包括過多的列也不行,因為覆蓋索引列的值是存儲在內(nèi)存中的,這樣會消耗過多內(nèi)存,引發(fā)性能下降。 創(chuàng)建覆蓋索引時使用數(shù)據(jù)庫調(diào)整顧問 我們知道,當SQL出問題時,SQL Server引擎中的優(yōu)化器根據(jù)下列因素自動生成不同的查詢計劃: 1)數(shù)據(jù)量 2)統(tǒng)計數(shù)據(jù) 3)索引變化 4)TSQL中的參數(shù)值 5)服務(wù)器負載 這就意味著,對于特定的SQL,即使表和索引結(jié)構(gòu)是一樣的,但在生產(chǎn)服務(wù)器和在測試服務(wù)器上產(chǎn)生的執(zhí)行計劃可能會不一樣,這也意味著在測試服務(wù)器上創(chuàng)建的索引可以提高應用程序的性能,但在生產(chǎn)服務(wù)器上創(chuàng)建同樣的索引卻未必會提高應用程序的性能。因為測試環(huán)境中的執(zhí)行計劃利用了新創(chuàng)建的索引,但在生產(chǎn)環(huán)境中執(zhí)行計劃可能不會利用新創(chuàng)建的索引(例如,一個非聚集索引列在生產(chǎn)環(huán)境中不是一個高選中性列,但在測試環(huán)境中可能就不一樣)。 因此我們在創(chuàng)建索引時,要知道執(zhí)行計劃是否會真正利用它,但我們怎么才能知道呢?答案就是在測試服務(wù)器上模擬生產(chǎn)環(huán)境負載,然后創(chuàng)建合適的索引并進行測試,如果這樣測試發(fā)現(xiàn)索引可以提高性能,那么它在生產(chǎn)環(huán)境也就更可能提高應用程序的性能了。 雖然要模擬一個真實的負載比較困難,但目前已經(jīng)有很多工具可以幫助我們。 使用SQL profiler跟蹤生產(chǎn)服務(wù)器,盡管不建議在生產(chǎn)環(huán)境中使用SQL profiler,但有時沒有辦法,要診斷性能問題關(guān)鍵所在,必須得用,在http://msdn.microsoft.com/en-us/library/ms181091.aspx有SQL profiler的使用方法。 使用SQL profiler創(chuàng)建的跟蹤文件,在測試服務(wù)器上利用數(shù)據(jù)庫調(diào)整顧問創(chuàng)建一個類似的負載,大多數(shù)時候,調(diào)整顧問會給出一些可以立即使用的索引建議,在http://msdn.microsoft.com/en-us/library/ms166575.aspx有調(diào)整顧問的詳細介紹。 第三步:整理索引碎片 你可能已經(jīng)創(chuàng)建好了索引,并且所有索引都在工作,但性能卻仍然不好,那很可能是產(chǎn)生了索引碎片,你需要進行索引碎片整理。 什么是索引碎片? 由于表上有過度地插入、修改和刪除操作,索引頁被分成多塊就形成了索引碎片,如果索引碎片嚴重,那掃描索引的時間就會變長,甚至導致索引不可用,因此數(shù)據(jù)檢索操作就慢下來了。 有兩種類型的索引碎片:內(nèi)部碎片和外部碎片。 內(nèi)部碎片:為了有效的利用內(nèi)存,使內(nèi)存產(chǎn)生更少的碎片,要對內(nèi)存分頁,內(nèi)存以頁為單位來使用,最后一頁往往裝不滿,于是形成了內(nèi)部碎片。 外部碎片:為了共享要分段,在段的換入換出時形成外部碎片,比如5K的段換出后,有一個4k的段進來放到原來5k的地方,于是形成1k的外部碎片。 如何知道是否發(fā)生了索引碎片? 執(zhí)行下面的SQL語句就知道了(下面的語句可以在SQL Server 2005及后續(xù)版本中運行,用你的數(shù)據(jù)庫名替換掉這里的AdventureWorks): SELECT object_name(dt.object_id) Tablename,si.name IndexName,dt.avg_fragmentation_in_percent AS ExternalFragmentation,dt.avg_page_space_used_in_percent AS InternalFragmentation FROM ( SELECT object_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats (db_id('AdventureWorks'),null,null,null,'DETAILED' ) WHERE index_id <> 0) AS dt INNER JOIN sys.indexes si ON si.object_id=dt.object_id AND si.index_id=dt.index_id AND dt.avg_fragmentation_in_percent>10 AND dt.avg_page_space_used_in_percent<75 ORDER BY avg_fragmentation_in_percent DESC 執(zhí)行后顯示AdventureWorks數(shù)據(jù)庫的索引碎片信息。 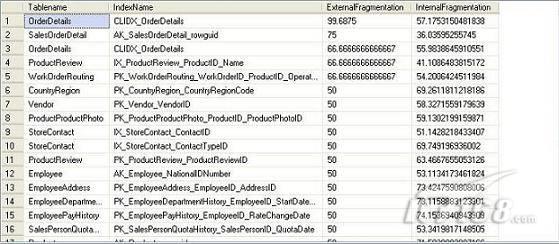 圖 3 索引碎片信息 使用下面的規(guī)則分析結(jié)果,你就可以找出哪里發(fā)生了索引碎片: 1)ExternalFragmentation的值>10表示對應的索引發(fā)生了外部碎片; 2)InternalFragmentation的值<75表示對應的索引發(fā)生了內(nèi)部碎片。 如何整理索引碎片? 有兩種整理索引碎片的方法: 1)重組有碎片的索引:執(zhí)行下面的命令 ALTER INDEX ALL ON TableName REORGANIZE 2)重建索引:執(zhí)行下面的命令 ALTER INDEX ALL ON TableName REBUILD WITH (FILLFACTOR=90,ONLINE=ON) 也可以使用索引名代替這里的“ALL”關(guān)鍵字重組或重建單個索引,也可以使用SQL Server管理工作臺進行索引碎片的整理。  圖 4 使用SQL Server管理工作臺整理索引碎片 什么時候用重組,什么時候用重建呢? 當對應索引的外部碎片值介于10-15之間,內(nèi)部碎片值介于60-75之間時使用重組,其它情況就應該使用重建。 值得注意的是重建索引時,索引對應的表會被鎖定,但重組不會鎖表,因此在生產(chǎn)系統(tǒng)中,對大表重建索引要慎重,因為在大表上創(chuàng)建索引可能會花幾個小時,幸運的是,從SQL Server 2005開始,微軟提出了一個解決辦法,在重建索引時,將ONLINE選項設(shè)置為ON,這樣可以保證重建索引時表仍然可以正常使用。 雖然索引可以提高查詢速度,但如果你的數(shù)據(jù)庫是一個事務(wù)型數(shù)據(jù)庫,大多數(shù)時候都是更新操作,更新數(shù)據(jù)也就意味著要更新索引,這個時候就要兼顧查詢和更新操作了,因為在OLTP數(shù)據(jù)庫表上創(chuàng)建過多的索引會降低整體數(shù)據(jù)庫性能。 我給大家一個建議:如果你的數(shù)據(jù)庫是事務(wù)型的,平均每個表上不能超過5個索引,如果你的數(shù)據(jù)庫是數(shù)據(jù)倉庫型,平均每個表可以創(chuàng)建10個索引都沒問題。 在前面我們介紹了如何正確使用索引,調(diào)整索引是見效最快的性能調(diào)優(yōu)方法,但一般而言,調(diào)整索引只會提高查詢性能。除此之外,我們還可以調(diào)整數(shù)據(jù)訪問代碼和TSQL,本文就介紹如何以最優(yōu)的方法重構(gòu)數(shù)據(jù)訪問代碼和TSQL。 第四步:將TSQL代碼從應用程序遷移到數(shù)據(jù)庫中 也許你不喜歡我的這個建議,你或你的團隊可能已經(jīng)有一個默認的潛規(guī)則,那就是使用ORM(Object Relational Mapping,即對象關(guān)系映射)生成所有SQL,并將SQL放在應用程序中,但如果你要優(yōu)化數(shù)據(jù)訪問性能,或需要調(diào)試應用程序性能問題,我建議你將SQL代碼移植到數(shù)據(jù)庫上(使用存儲過程,視圖,函數(shù)和觸發(fā)器),原因如下: 1、使用存儲過程,視圖,函數(shù)和觸發(fā)器實現(xiàn)應用程序中SQL代碼的功能有助于減少應用程序中SQL復制的弊端,因為現(xiàn)在只在一個地方集中處理SQL,為以后的代碼復用打下了良好的基礎(chǔ)。 2、使用數(shù)據(jù)庫對象實現(xiàn)所有的TSQL有助于分析TSQL的性能問題,同時有助于你集中管理TSQL代碼。 3、將TS QL移植到數(shù)據(jù)庫上去后,可以更好地重構(gòu)TSQL代碼,以利用數(shù)據(jù)庫的高級索引特性。此外,應用程序中沒了SQL代碼也將更加簡潔。 雖然這一步可能不會象前三步那樣立竿見影,但做這一步的主要目的是為后面的優(yōu)化步驟打下基礎(chǔ)。如果在你的應用程序中使用ORM(如NHibernate)實現(xiàn)了數(shù)據(jù)訪問例行程序,在測試或開發(fā)環(huán)境中你可能發(fā)現(xiàn)它們工作得很好,但在生產(chǎn)數(shù)據(jù)庫上卻可能遇到問題,這時你可能需要反思基于ORM的數(shù)據(jù)訪問邏輯,利用TSQL對象實現(xiàn)數(shù)據(jù)訪問例行程序是一種好辦法,這樣做有更多的機會從數(shù)據(jù)庫角度來優(yōu)化性能。 我向你保證,如果你花1-2人月來完成遷移,那以后肯定不止節(jié)約1-2人年的的成本。 OK!假設(shè)你已經(jīng)照我的做的了,完全將TSQL遷移到數(shù)據(jù)庫上去了,下面就進入正題吧! 第五步:識別低效TSQL,采用最佳實踐重構(gòu)和應用TSQL 由于每個程序員的能力和習慣都不一樣,他們編寫的TSQL可能風格各異,部分代碼可能不是最佳實現(xiàn),對于水平一般的程序員可能首先想到的是編寫TSQL實現(xiàn)需求,至于性能問題日后再說,因此在開發(fā)和測試時可能發(fā)現(xiàn)不了問題。 也有一些人知道最佳實踐,但在編寫代碼時由于種種原因沒有采用最佳實踐,等到用戶發(fā)飆的那天才乖乖地重新埋頭思考最佳實踐。 我覺得還是有必要介紹一下具有都有哪些最佳實踐。 1、在查詢中不要使用“select *” (1)檢索不必要的列會帶來額外的系統(tǒng)開銷,有句話叫做“該省的則省”; (2)數(shù)據(jù)庫不能利用“覆蓋索引”的優(yōu)點,因此查詢緩慢。 2、在select清單中避免不必要的列,在連接條件中避免不必要的表 (1)在select查詢中如有不必要的列,會帶來額外的系統(tǒng)開銷,特別是LOB類型的列; (2)在連接條件中包含不必要的表會強制數(shù)據(jù)庫引擎檢索和匹配不需要的數(shù)據(jù),增加了查詢執(zhí)行時間。 3、不要在子查詢中使用count()求和執(zhí)行存在性檢查 (1)不要使用 SELECT column_list FROM table WHERE 0 < (SELECT count(*) FROM table2 WHERE ..) 使用 SELECT column_list FROM table WHERE EXISTS (SELECT * FROM table2 WHERE ...) 代替; (2)當你使用count()時,SQL Server不知道你要做的是存在性檢查,它會計算所有匹配的值,要么會執(zhí)行全表掃描,要么會掃描最小的非聚集索引; (3)當你使用EXISTS時,SQL Server知道你要執(zhí)行存在性檢查,當它發(fā)現(xiàn)第一個匹配的值時,就會返回TRUE,并停止查詢。類似的應用還有使用IN或ANY代替count()。 4、避免使用兩個不同類型的列進行表的連接 (1)當連接兩個不同類型的列時,其中一個列必須轉(zhuǎn)換成另一個列的類型,級別低的會被轉(zhuǎn)換成高級別的類型,轉(zhuǎn)換操作會消耗一定的系統(tǒng)資源; (2)如果你使用兩個不同類型的列來連接表,其中一個列原本可以使用索引,但經(jīng)過轉(zhuǎn)換后,優(yōu)化器就不會使用它的索引了。例如: SELECT column_list FROM small_table, large_table WHERE smalltable.float_column = large_table.int_column 在這個例子中,SQL Server會將int列轉(zhuǎn)換為float類型,因為int比float類型的級別低,large_table.int_column上的索引就不會被使用,但smalltable.float_column上的索引可以正常使用。 5、避免死鎖 (1)在你的存儲過程和觸發(fā)器中訪問同一個表時總是以相同的順序; (2)事務(wù)應經(jīng)可能地縮短,在一個事務(wù)中應盡可能減少涉及到的數(shù)據(jù)量; (3)永遠不要在事務(wù)中等待用戶輸入。 6、使用“基于規(guī)則的方法”而不是使用“程序化方法”編寫TSQL (1)數(shù)據(jù)庫引擎專門為基于規(guī)則的SQL進行了優(yōu)化,因此處理大型結(jié)果集時應盡量避免使用程序化的方法(使用游標或UDF[User Defined Functions]處理返回的結(jié)果集) ; (2)如何擺脫程序化的SQL呢?有以下方法: - 使用內(nèi)聯(lián)子查詢替換用戶定義函數(shù); - 使用相關(guān)聯(lián)的子查詢替換基于游標的代碼; - 如果確實需要程序化代碼,至少應該使用表變量代替游標導航和處理結(jié)果集。 7、避免使用count(*)獲得表的記錄數(shù) (1)為了獲得表中的記錄數(shù),我們通常使用下面的SQL語句: SELECT COUNT(*) FROM dbo.orders 這條語句會執(zhí)行全表掃描才能獲得行數(shù)。 (2)但下面的SQL語句不會執(zhí)行全表掃描一樣可以獲得行數(shù): SELECT rows FROM sysindexes WHERE id = OBJECT_ID('dbo.Orders') AND indid < 2 8、避免使用動態(tài)SQL 除非迫不得已,應盡量避免使用動態(tài)SQL,因為: (1)動態(tài)SQL難以調(diào)試和故障診斷; (2)如果用戶向動態(tài)SQL提供了輸入,那么可能存在SQL注入風險。 9、避免使用臨時表 (1)除非卻有需要,否則應盡量避免使用臨時表,相反,可以使用表變量代替; (2)大多數(shù)時候(99%),表變量駐扎在內(nèi)存中,因此速度比臨時表更快,臨時表駐扎在TempDb數(shù)據(jù)庫中,因此臨時表上的操作需要跨數(shù)據(jù)庫通信,速度自然慢。 10、使用全文搜索搜索文本數(shù)據(jù),取代like搜索 全文搜索始終優(yōu)于like搜索: (1)全文搜索讓你可以實現(xiàn)like不能完成的復雜搜索,如搜索一個單詞或一個短語,搜索一個與另一個單詞或短語相近的單詞或短語,或者是搜索同義詞; (2)實現(xiàn)全文搜索比實現(xiàn)like搜索更容易(特別是復雜的搜索); 11、使用union實現(xiàn)or操作 (1)在查詢中盡量不要使用or,使用union合并兩個不同的查詢結(jié)果集,這樣查詢性能會更好; (2)如果不是必須要不同的結(jié)果集,使用union all效果會更好,因為它不會對結(jié)果集排序。 12、為大對象使用延遲加載策略 (1)在不同的表中存儲大對象(如VARCHAR(MAX),Image,Text等),然后在主表中存儲這些大對象的引用; (2)在查詢中檢索所有主表數(shù)據(jù),如果需要載入大對象,按需從大對象表中檢索大對象。 13、使用VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX) (1)在SQL Server 2000中,一行的大小不能超過800字節(jié),這是受SQL Server內(nèi)部頁面大小8KB的限制造成的,為了在單列中存儲更多的數(shù)據(jù),你需要使用TEXT,NTEXT或IMAGE數(shù)據(jù)類型(BLOB); (2)這些和存儲在相同表中的其它數(shù)據(jù)不一樣,這些頁面以B-Tree結(jié)構(gòu)排列,這些數(shù)據(jù)不能作為存儲過程或函數(shù)中的變量,也不能用于字符串函數(shù),如REPLACE,CHARINDEX或SUBSTRING,大多數(shù)時候你必須使用READTEXT,WRITETEXT和UPDATETEXT; (3)為了解決這個問題,在SQL Server 2005中增加了VARCHAR(MAX),VARBINARY(MAX) 和 NVARCHAR(MAX),這些數(shù)據(jù)類型可以容納和BLOB相同數(shù)量的數(shù)據(jù)(2GB),和其它數(shù)據(jù)類型使用相同的數(shù)據(jù)頁; (4)當MAX數(shù)據(jù)類型中的數(shù)據(jù)超過8KB時,使用溢出頁(在ROW_OVERFLOW分配單元中)指向源數(shù)據(jù)頁,源數(shù)據(jù)頁仍然在IN_ROW分配單元中。 14、在用戶定義函數(shù)中使用下列最佳實踐 不要在你的存儲過程,觸發(fā)器,函數(shù)和批處理中重復調(diào)用函數(shù),例如,在許多時候,你需要獲得字符串變量的長度,無論如何都不要重復調(diào)用LEN函數(shù),只調(diào)用一次即可,將結(jié)果存儲在一個變量中,以后就可以直接使用了。 15、在存儲過程中使用下列最佳實踐 (1)不要使用SP_xxx作為命名約定,它會導致額外的搜索,增加I/O(因為系統(tǒng)存儲過程的名字就是以SP_開頭的),同時這么做還會增加與系統(tǒng)存儲過程名稱沖突的幾率; (2)將Nocount設(shè)置為On避免額外的網(wǎng)絡(luò)開銷; (3)當索引結(jié)構(gòu)發(fā)生變化時,在EXECUTE語句中(第一次)使用WITH RECOMPILE子句,以便存儲過程可以利用最新創(chuàng)建的索引; (4)使用默認的參數(shù)值更易于調(diào)試。 16、在觸發(fā)器中使用下列最佳實踐 (1)最好不要使用觸發(fā)器,觸發(fā)一個觸發(fā)器,執(zhí)行一個觸發(fā)器事件本身就是一個耗費資源的過程; (2)如果能夠使用約束實現(xiàn)的,盡量不要使用觸發(fā)器; (3)不要為不同的觸發(fā)事件(Insert,Update和Delete)使用相同的觸發(fā)器; (4)不要在觸發(fā)器中使用事務(wù)型代碼。 17、在視圖中使用下列最佳實踐 (1)為重新使用復雜的TSQL塊使用視圖,并開啟索引視圖; (2)如果你不想讓用戶意外修改表結(jié)構(gòu),使用視圖時加上SCHEMABINDING選項; (3)如果只從單個表中檢索數(shù)據(jù),就不需要使用視圖了,如果在這種情況下使用視圖反倒會增加系統(tǒng)開銷,一般視圖會涉及多個表時才有用。 18、在事務(wù)中使用下列最佳實踐 (1)SQL Server 2005之前,在BEGIN TRANSACTION之后,每個子查詢修改語句時,必須檢查@@ERROR的值,如果值不等于0,那么最后的語句可能會導致一個錯誤,如果發(fā)生任何錯誤,事務(wù)必須回滾。從SQL Server 2005開始,Try..Catch..代碼塊可以處理TSQL中的事務(wù),因此在事務(wù)型代碼中最好加上Try…Catch…; (2)避免使用嵌套事務(wù),使用@@TRANCOUNT變量檢查事務(wù)是否需要啟動(為了避免嵌套事務(wù)); (3)盡可能晚啟動事務(wù),提交和回滾事務(wù)要盡可能快,以減少資源鎖定時間。 要完全列舉最佳實踐不是本文的初衷,當你了解了這些技巧后就應該拿來使用,否則了解了也沒有價值。此外,你還需要評審和監(jiān)視數(shù)據(jù)訪問代碼是否遵循下列標準和最佳實踐。 如何分析和識別你的TSQL中改進的范圍? 理想情況下,大家都想預防疾病,而不是等病發(fā)了去治療。但實際上這個愿望根本無法實現(xiàn),即使你的團隊成員全都是專家級人物,我也知道你有進行評審,但代碼仍然一團糟,因此需要知道如何治療疾病一樣重要。 首先需要知道如何診斷性能問題,診斷就得分析TSQL,找出瓶頸,然后重構(gòu),要找出瓶頸就得先學會分析執(zhí)行計劃。 理解查詢執(zhí)行計劃 當你將SQL語句發(fā)給SQL Server引擎后,SQL Server首先要確定最合理的執(zhí)行方法,查詢優(yōu)化器會使用很多信息,如數(shù)據(jù)分布統(tǒng)計,索引結(jié)構(gòu),元數(shù)據(jù)和其它信息,分析多種可能的執(zhí)行計劃,最后選擇一個最佳的執(zhí)行計劃。 可以使用SQL Server Management Studio預覽和分析執(zhí)行計劃,寫好SQL語句后,點擊SQL Server Management Studio上的評估執(zhí)行計劃按鈕查看執(zhí)行計劃,如圖1所示。 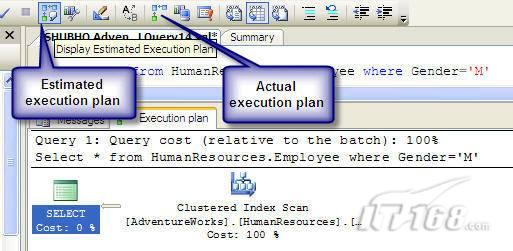 圖 1 在Management Studio中評估執(zhí)行計劃 在執(zhí)行計劃圖中的每個圖標代表計劃中的一個行為(操作),應從右到左閱讀執(zhí)行計劃,每個行為都一個相對于總體執(zhí)行成本(100%)的成本百分比。 在上面的執(zhí)行計劃圖中,右邊的那個圖標表示在HumanResources表上的一個“聚集索引掃描”操作(閱讀表中所有主鍵索引值),需要100%的總體查詢執(zhí)行成本,圖中左邊那個圖標表示一個select操作,它只需要0%的總體查詢執(zhí)行成本。 下面是一些比較重要的圖標及其對應的操作: 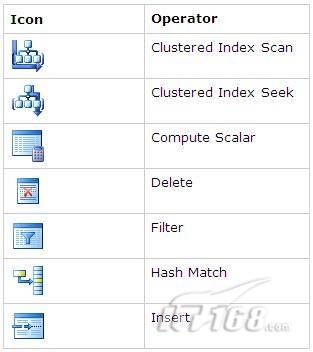 圖 2 常見的重要圖標及對應的操作 注意執(zhí)行計劃中的查詢成本,如果說成本等于100%,那很可能在批處理中就只有這個查詢,如果在一個查詢窗口中有多個查詢同時執(zhí)行,那它們肯定有各自的成本百分比(小于100%)。 如果想知道執(zhí)行計劃中每個操作詳細情況,將鼠標指針移到對應的圖標上即可,你會看到類似于下面的這樣一個窗口。 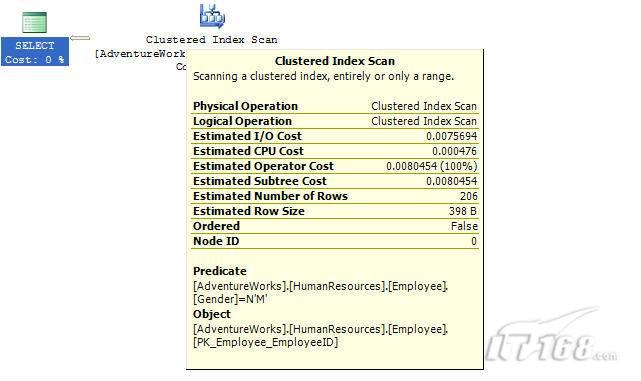 圖 3 查看執(zhí)行計劃中行為(操作)的詳細信息 這個窗口提供了詳細的評估信息,上圖顯示了聚集索引掃描的詳細信息,它要查找AdventureWorks數(shù)據(jù)庫HumanResources方案下Employee表中 Gender = ‘M’的行,它也顯示了評估的I/O,CPU成本。 查看執(zhí)行計劃時,我們應該獲得什么信息 當你的查詢很慢時,你就應該看看預估的執(zhí)行計劃(當然也可以查看真實的執(zhí)行計劃),找出耗時最多的操作,注意觀察以下成本通常較高的操作: 1、表掃描(Table Scan) 當表沒有聚集索引時就會發(fā)生,這時只要創(chuàng)建聚集索引或重整索引一般都可以解決問題。 2、聚集索引掃描(Clustered Index Scan) 有時可以認為等同于表掃描,當某列上的非聚集索引無效時會發(fā)生,這時只要創(chuàng)建一個非聚集索引就ok了。 3、哈希連接(Hash Join) 當連接兩個表的列沒有被索引時會發(fā)生,只需在這些列上創(chuàng)建索引即可。 4、嵌套循環(huán)(Nested Loops) 當非聚集索引不包括select查詢清單的列時會發(fā)生,只需要創(chuàng)建覆蓋索引問題即可解決。 5、RID查找(RID Lookup) 當你有一個非聚集索引,但相同的表上卻沒有聚集索引時會發(fā)生,此時數(shù)據(jù)庫引擎會使用行ID查找真實的行,這時一個代價高的操作,這時只要在該表上創(chuàng)建聚集索引即可。 TSQL重構(gòu)真實的故事 只有解決了實際的問題后,知識才轉(zhuǎn)變?yōu)閮r值。當我們檢查應用程序性能時,發(fā)現(xiàn)一個存儲過程比我們預期的執(zhí)行得慢得多,在生產(chǎn)數(shù)據(jù)庫中檢索一個月的銷售數(shù)據(jù)居然要50秒,下面就是這個存儲過程的執(zhí)行語句: exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009,’Cap’ Tom受命來優(yōu)化這個存儲過程,下面是這個存儲過程的代碼: ALTER PROCEDURE uspGetSalesInfoForDateRange @startYear DateTime, @endYear DateTime, @keyword nvarchar(50) AS BEGIN SET NOCOUNT ON; SELECT Name, ProductNumber, ProductRates.CurrentProductRate Rate, ProductRates.CurrentDiscount Discount, OrderQty Qty, dbo.ufnGetLineTotal(SalesOrderDetailID) Total, OrderDate, DetailedDescription FROM Products INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON Orders.SalesOrderID = OrderDetails.SalesOrderID INNER JOIN ProductRates ON Products.ProductID = ProductRates.ProductID WHERE OrderDate between @startYear and @endYear AND ( ProductName LIKE '' + @keyword + ' %' OR ProductName LIKE '% ' + @keyword + ' ' + '%' OR ProductName LIKE '% ' + @keyword + '%' OR Keyword LIKE '' + @keyword + ' %' OR Keyword LIKE '% ' + @keyword + ' ' + '%' OR Keyword LIKE '% ' + @keyword + '%' ) ORDER BY ProductName END GO 分析索引 首先,Tom想到了審查這個存儲過程使用到的表的索引,很快他發(fā)現(xiàn)下面兩列的索引無故丟失了: OrderDetails.ProductID OrderDetails.SalesOrderID 他在這兩個列上創(chuàng)建了非聚集索引,然后再執(zhí)行存儲過程: exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009 with recompile 性能有所改變,但仍然低于預期(這次花了35秒),注意這里的with recompile子句告訴SQL Server引擎重新編譯存儲過程,重新生成執(zhí)行計劃,以利用新創(chuàng)建的索引。 分析查詢執(zhí)行計劃 Tom接下來查看了SQL Server Management Studio中的執(zhí)行計劃,通過分析,他找到了某些重要的線索: 1、發(fā)生了一次表掃描,即使該表已經(jīng)正確設(shè)置了索引,而表掃描占據(jù)了總體查詢執(zhí)行時間的30%; 2、發(fā)生了一個嵌套循環(huán)連接。 Tom想知道是否有索引碎片,因為所有索引配置都是正確的,通過TSQL他知道了有兩個索引都產(chǎn)生了碎片,很快他重組了這兩個索引,于是表掃描消失了,現(xiàn)在執(zhí)行存儲過程的時間減少到25秒了。 為了消除嵌套循環(huán)連接,他又在表上創(chuàng)建了覆蓋索引,時間進一步減少到23秒。 實施最佳實踐 Tom發(fā)現(xiàn)有個UDF有問題,代碼如下: ALTER FUNCTION [dbo].[ufnGetLineTotal] ( @SalesOrderDetailID int ) RETURNS money AS BEGIN DECLARE @CurrentProductRate money DECLARE @CurrentDiscount money DECLARE @Qty int SELECT @CurrentProductRate = ProductRates.CurrentProductRate, @CurrentDiscount = ProductRates.CurrentDiscount, @Qty = OrderQty FROM ProductRates INNER JOIN OrderDetails ON OrderDetails.ProductID = ProductRates.ProductID WHERE OrderDetails.SalesOrderDetailID = @SalesOrderDetailID RETURN (@CurrentProductRate-@CurrentDiscount)*@Qty END 在計算訂單總金額時看起來代碼很程序化,Tom決定在UDF的SQL中使用內(nèi)聯(lián)SQL。 dbo.ufnGetLineTotal(SalesOrderDetailID) Total -- 舊代碼 (CurrentProductRate-CurrentDiscount)*OrderQty Total -- 新代碼 執(zhí)行時間一下子減少到14秒了。 在select查詢清單中放棄不必要的Text列 為了進一步提升性能,Tom決定檢查一下select查詢清單中使用的列,很快他發(fā)現(xiàn)有一個Products.DetailedDescription列是Text類型,通過對應用程序代碼的走查,Tom發(fā)現(xiàn)其實這一列的數(shù)據(jù)并不會立即用到,于是他將這一列從select查詢清單中取消掉,時間一下子從14秒減少到6秒,于是Tom決定使用一個存儲過程應用延遲加載策略加載這個Text列。 最后Tom還是不死心,認為6秒也無法接受,于是他再次仔細檢查了SQL代碼,他發(fā)現(xiàn)了一個like子句,經(jīng)過反復研究他認為這個like搜索完全可以用全文搜索替換,最后他用全文搜索替換了like搜索,時間一下子降低到1秒,至此Tom認為調(diào)優(yōu)應該暫時結(jié)束了。 小結(jié) 看起來我們介紹了好多種優(yōu)化數(shù)據(jù)訪問的技巧,但大家要知道優(yōu)化數(shù)據(jù)訪問是一個無止境的過程,同樣大家要相信一個信念,無論你的系統(tǒng)多么龐大,多么復雜,只要靈活運用我們所介紹的這些技巧,你一樣可以馴服它們。下一篇將介紹高級索引和反范式化。 經(jīng)過索引優(yōu)化,重構(gòu)TSQL后你的數(shù)據(jù)庫還存在性能問題嗎?完全有可能,這時必須得找另外的方法才行。SQL Server在索引方面還提供了某些高級特性,可能你還從未使用過,利用高級索引會顯著地改善系統(tǒng)性能,本文將從高級索引技術(shù)談起,另外還將介紹反范式化技術(shù)。 第六步:應用高級索引 實施計算列并在這些列上創(chuàng)建索引 你可能曾經(jīng)寫過從數(shù)據(jù)庫查詢一個結(jié)果集的應用程序代碼,對結(jié)果集中每一行進行計算生成最終顯示輸出的信息。例如,你可能有一個查詢從數(shù)據(jù)庫檢索訂單信息,在應用程序代碼中你可能已經(jīng)通過對產(chǎn)品和銷售量執(zhí)行算術(shù)操作計算出了總的訂單價格,但為什么你不在數(shù)據(jù)庫中執(zhí)行這些操作呢? 請看下面這張圖,你可以通過指定一個公式將一個數(shù)據(jù)庫表列作為計算列,你的TSQL在查詢清單中包括這個計算列,SQL引擎將會應用這個公式計算出這一列的值,在執(zhí)行查詢時,數(shù)據(jù)庫引擎將會計算訂單總價,并為計算列返回結(jié)果。  圖 1 計算列 使用計算列你可以將計算工作全部交給后端執(zhí)行,但如果表的行數(shù)太多可能計算性能也不高,如果計算列出現(xiàn)在Select查詢的where子句中情況會更糟,在這種情況下,為了匹配where子句指定的值,數(shù)據(jù)庫引擎不得不計算表中所有行中計算列的值,這是一個低效的過程,因為它總是需要全表掃描或全聚集索引掃描。 因此問題就來了,如何提高計算列的性能呢?解決辦法是在計算列上創(chuàng)建索引,當計算列上有索引后,SQL Server會提前計算結(jié)果,然后在結(jié)果之上構(gòu)建索引。此外,當對應列(計算列依賴的列)的值更新時,計算列上的索引值也會更新。因此,在執(zhí)行查詢時,數(shù)據(jù)庫引擎不會為結(jié)果集中的每一行都執(zhí)行一次計算公式,相反,通過索引可直接獲得計算列預先計算出的值,因此在計算列上創(chuàng)建一個索引將會加快查詢速度。 提示:如果你想在計算列上創(chuàng)建索引,必須確保計算列上的公式不能包括任何“非確定的”函數(shù),例如getdate()就是一個非確定的函數(shù),因為每次調(diào)用它,它返回的值都是不一樣的。 創(chuàng)建索引視圖 你是否知道可以在視圖上創(chuàng)建索引?OK,不知道沒關(guān)系,看了我的介紹你就明白了。 為什么要使用視圖? 大家都知道,視圖本身不存儲任何數(shù)據(jù),只是一條編譯的select語句。數(shù)據(jù)庫會為視圖生成一個執(zhí)行計劃,視圖是可以重復使用的,因為執(zhí)行計劃也可以重復使用。 視圖本身不會帶來性能的提升,我曾經(jīng)以為它會“記住”查詢結(jié)果,但后來我才知道它除了是一個編譯了的查詢外,其它什么都不是,視圖根本記不住查詢結(jié)果,我敢打賭好多剛接觸SQL的人都會有這個錯誤的想法。 但是現(xiàn)在我要告訴你一個方法讓視圖記住查詢結(jié)果,其實非常簡單,就是在視圖上創(chuàng)建索引就可以了。 如果你在視圖上應用了索引,視圖就成為索引視圖,對于一個索引視圖,數(shù)據(jù)庫引擎處理SQL,并在數(shù)據(jù)文件中存儲結(jié)果,和聚集表類似,當基礎(chǔ)表中的數(shù)據(jù)發(fā)生變化時,SQL Server會自動維護索引,因此當你在索引視圖上查詢時,數(shù)據(jù)庫引擎簡單地從索引中查找值,速度當然就很快了,因此在視圖上創(chuàng)建索引可以明顯加快查詢速度。 但請注意,天下沒有免費的午餐,創(chuàng)建索引視圖可以提升性能,當基礎(chǔ)表中的數(shù)據(jù)發(fā)生變化時,數(shù)據(jù)庫引擎也會更新索引,因此,當視圖要處理很多行,且要求和,當數(shù)據(jù)和基礎(chǔ)表不經(jīng)常發(fā)生變化時,就應該考慮創(chuàng)建索引視圖。 如何創(chuàng)建索引視圖? 1)創(chuàng)建/修改視圖時指定SCHEMABINDING選項: REATE VIEW dbo.vOrderDetails WITH SCHEMABINDING AS SELECT… 2)在視圖上創(chuàng)建一個唯一的聚集索引; 3)視需要在視圖上創(chuàng)建一個非聚集索引。 不是所有視圖上都可以創(chuàng)建索引,在視圖上創(chuàng)建索引存在以下限制: 1)創(chuàng)建視圖時使用了SCHEMABINDING選項,這種情況下,數(shù)據(jù)庫引擎不允許你改變表的基礎(chǔ)結(jié)構(gòu); 2)視圖不能包含任何非確定性函數(shù),DISTINCT子句和子查詢; 3)視圖中的底層表必須由聚集索引(主鍵)。 如果你發(fā)現(xiàn)你的應用程序中使用的TSQL是用視圖實現(xiàn)的,但存在性能問題,那此時給視圖加上索引可能會帶來性能的提升。 為用戶定義函數(shù)(UDF)創(chuàng)建索引 在用戶定義函數(shù)上也可以創(chuàng)建索引,但不能直接在它上面創(chuàng)建索引,需要創(chuàng)建一個輔助的計算列,公式就使用用戶定義函數(shù),然后在這個計算列字段上創(chuàng)建索引。具體步驟如下: 1)首先創(chuàng)建一個確定性的函數(shù)(如果不存在的話),在函數(shù)定義中添加SCHEMABINDING選項,如: CREATE FUNCTION [dbo.ufnGetLineTotal] ( -- Add the parameters for the function here @UnitPrice [money], @UnitPriceDiscount [money], @OrderQty [smallint] ) RETURNS money WITH SCHEMABINDING AS BEGIN return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty)) END 2)在目標表上增加一個計算列,使用前面定義的函數(shù)作為該列的計算公式,如圖2所示。 CREATE FUNCTION [dbo.ufnGetLineTotal] ( -- Add the parameters for the function here @UnitPrice [money], @UnitPriceDiscount [money], @OrderQty [smallint] ) RETURNS money WITH SCHEMABINDING AS BEGIN return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty)) END 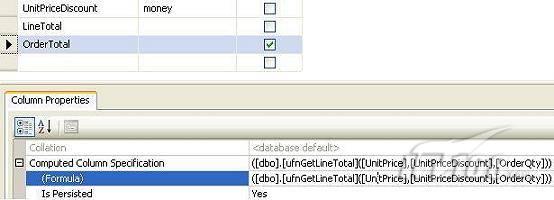 圖 2 指定UDF為計算列的結(jié)算公式 3)在計算列上創(chuàng)建索引 當你的查詢中包括UDF時,如果在該UDF上創(chuàng)建了以計算列為基礎(chǔ)的索引,特別是兩個表或視圖的連接條件中使用了UDF,性能都會有明顯的改善。 在XML列上創(chuàng)建索引 在SQL Server(2005和后續(xù)版本)中,XML列是以二進制大對象(BLOB)形式存儲的,可以使用XQuery進行查詢,但如果沒有索引,每次查詢XML數(shù)據(jù)類型時都非常耗時,特別是大型XML實例,因為SQL Server在運行時需要分隔二進制大對象評估查詢。為了提升XML數(shù)據(jù)類型上的查詢性能,XML列可以索引,XML索引分為兩類。 主XML索引 創(chuàng)建XML列上的主索引時,SQL Server會切碎XML內(nèi)容,創(chuàng)建多個數(shù)據(jù)行,包括元素,屬性名,路徑,節(jié)點類型和值等,創(chuàng)建主索引讓SQL Server更輕松地支持XQuery請求。下面是創(chuàng)建一個主XML索引的示例語法。 CREATE PRIMARY XML INDEX index_name ON <object> ( xml_column ) 次要XML索引 雖然XML數(shù)據(jù)已經(jīng)被切條,但SQL Server仍然要掃描所有切條的數(shù)據(jù)才能找到想要的結(jié)果,為了進一步提升性能,還需要在主XML索引之上創(chuàng)建次要XML索引。有三種次要XML索引。 1)“路徑”(Path)次要XML索引:使用.exist()方法確定一個特定的路徑是否存在時它很有用; 2)“值”(Value)次要XML索引:用于執(zhí)行基于值的查詢,但不知道完整的路徑或路徑包括通配符時; 3)“屬性”(Secondary)次要XML索引:知道路徑時檢索屬性的值。 下面是一個創(chuàng)建次要XML索引的示例: CREATE XML INDEX index_name ON <object> ( xml_column ) USING XML INDEX primary_xml_index_name FOR { VALUE | PATH | PROPERTY } 請注意,上面講的原則是基礎(chǔ),如果盲目地在表上創(chuàng)建索引,不一定會提升性能,因為有時在某些表的某些列上創(chuàng)建索引時,可能會致使插入和更新操作變慢,當這個表上有一個低選中性列時更是如此,同樣,當表中的記錄很少(如<500)時,如果在這樣的表上創(chuàng)建索引反倒會使數(shù)據(jù)檢索性能降低,因為對于小表而言,全表掃描反而會更快,因此在創(chuàng)建索引時應放聰明一點。 第七步:應用反范式化,使用歷史表和預計算列 反范式化 如果你正在為一個OLTA(在線事務(wù)分析)系統(tǒng)設(shè)計數(shù)據(jù)庫,主要指為只讀查詢優(yōu)化過的數(shù)據(jù)倉庫,你可以(和應該)在你的數(shù)據(jù)庫中應用反范式化和索引,也就是說,某些數(shù)據(jù)可以跨多個表存儲,但報告和數(shù)據(jù)分析查詢在這種數(shù)據(jù)庫上可能會更快。 但如果你正在為一個OLTP(聯(lián)機事務(wù)處理)系統(tǒng)設(shè)計數(shù)據(jù)庫,這樣的數(shù)據(jù)庫主要執(zhí)行數(shù)據(jù)更新操作(包括插入/更新/刪除),我建議你至少實施第一、二、三范式,這樣數(shù)據(jù)冗余可以降到最低,數(shù)據(jù)存儲也可以達到最小化,可管理性也會好一點。 無論我們在OLTP系統(tǒng)上是否應用范式,在數(shù)據(jù)庫上總有大量的讀操作(即select查詢),當應用了所有優(yōu)化技術(shù)后,如果發(fā)現(xiàn)數(shù)據(jù)檢索操作仍然效率低下,此時,你可能需要考慮應用反范式設(shè)計了,但問題是如何應用反范式化,以及為什么應用反范式化會提升性能?讓我們來看一個簡單的例子,答案就在例子中。 假設(shè)我們有兩個表OrderDetails(ID,ProductID,OrderQty) 和 Products(ID,ProductName)分別存儲訂單詳細信息和產(chǎn)品信息,現(xiàn)在要查詢某個客戶訂購的產(chǎn)品名稱和它們的數(shù)量,查詢SQL語句如下: SELECT Products.ProductName,OrderQty FROM OrderDetails INNER JOIN Products ON OrderDetails.ProductID = Products.ProductID WHERE SalesOrderID = 47057 如果這兩個都是大表,當你應用了所有優(yōu)化技巧后,查詢速度仍然很慢,這時可以考慮以下反范式化設(shè)計: 1)在OrderDetails表上添加一列ProductName,并填充好數(shù)據(jù); 2)重寫上面的SQL語句 SELECT ProductName,OrderQty FROM OrderDetails WHERE SalesOrderID = 47057 注意在OrderDetails表上應用了反范式化后,不再需要連接Products表,因此在執(zhí)行SQL時,SQL引擎不會執(zhí)行兩個表的連接操作,查詢速度當然會快一些。 為了提高select操作性能,我們不得不做出一些犧牲,需要在兩個地方(OrderDetails 和 Products表)存儲相同的數(shù)據(jù)(ProductName),當我們插入或更新Products 表中的ProductName字段時,不得不同步更新OrderDetails表中的ProductName字段,此外,應用這種反范式化設(shè)計時會增加存儲資源消耗。 因此在實施反范式化設(shè)計時,我們必須在數(shù)據(jù)冗余和查詢操作性能之間進行權(quán)衡,同時在應用反范式化后,我們不得不重構(gòu)某些插入和更新操作代碼。有一個重要的原則需要遵守,那就是只有當你應用了所有其它優(yōu)化技術(shù)都還不能將性能提升到理想情況時才使用反范式化。同時還需注意不能使用太多的反范式化設(shè)計,那樣會使原本清晰的表結(jié)構(gòu)設(shè)計變得越來模糊。 歷史表 如果你的應用程序中有定期運行的數(shù)據(jù)檢索操作(如報表),如果涉及到大表的檢索,可以考慮定期將事務(wù)型規(guī)范化表中的數(shù)據(jù)復制到反范式化的單一的歷史表中,如利用數(shù)據(jù)庫的Job來完成這個任務(wù),并對這個歷史表建立合適的索引,那么周期性執(zhí)行的數(shù)據(jù)檢索操作可以遷移到這個歷史表上,對單個歷史表的查詢性能肯定比連接多個事務(wù)表的查詢速度要快得多。 例如,假設(shè)有一個連鎖商店的月度報表需要3個小時才能執(zhí)行完畢,你被派去優(yōu)化這個報表,目的只有一個:最小化執(zhí)行時間。那么你除了應用其它優(yōu)化技巧外,還可以采取以下手段: 1)使用反范式化結(jié)構(gòu)創(chuàng)建一個歷史表,并對銷售數(shù)據(jù)建立合適的索引; 2)在SQL Server上創(chuàng)建一個定期執(zhí)行的操作,每隔24小時運行一次,在半夜往歷史表中填充數(shù)據(jù); 3)修改報表代碼,從歷史表獲取數(shù)據(jù)。 創(chuàng)建定期執(zhí)行的操作 按照下面的步驟在SQL Server中創(chuàng)建一個定期執(zhí)行的操作,定期從事務(wù)表中提取數(shù)據(jù)填充到歷史表中。 1)首先確保SQL Server代理服務(wù)處于運行狀態(tài); 2)在SQL Server配置管理器中展開SQL Server代理節(jié)點,在“作業(yè)”節(jié)點上創(chuàng)建一個新作業(yè),在“常規(guī)”標簽頁中,輸入作業(yè)名稱和描述文字; 3)在“步驟”標簽頁中,點擊“新建”按鈕創(chuàng)建一個新的作業(yè)步驟,輸入名字和TSQL代碼,最后保存; 4)切換到“調(diào)度”標簽頁,點擊“新建”按鈕創(chuàng)建一個新調(diào)度計劃; 5)最后保存調(diào)度計劃。 在數(shù)據(jù)插入和更新中提前執(zhí)行耗時的計算,簡化查詢 大多數(shù)情況下,你會看到你的應用程序是一個接一個地執(zhí)行數(shù)據(jù)插入或更新操作,一次只涉及到一條記錄,但數(shù)據(jù)檢索操作可能同時涉及到多條記錄。 如果你的查詢中包括一個復雜的計算操作,毫無疑問這將導致整體的查詢性能下降,你可以考慮下面的解決辦法: 1)在表中創(chuàng)建額外的一列,包含計算的值; 2)為插入和更新事件創(chuàng)建一個觸發(fā)器,使用相同的計算邏輯計算值,計算完成后更新到新建的列; 3)使用新創(chuàng)建的列替換查詢中的計算邏輯。 實施完上述步驟后,插入和更新操作可能會更慢一點,因為每次插入和更新時觸發(fā)器都會執(zhí)行一下,但數(shù)據(jù)檢索操作會比之前快得多,因為執(zhí)行查詢時,數(shù)據(jù)庫引擎不會執(zhí)行計算操作了。 小結(jié) 至此,我們已經(jīng)應用了索引,重構(gòu)TSQL,應用高級索引,反范式化,以及歷史表加速數(shù)據(jù)檢索速度,但性能優(yōu)化是一個永無終點的過程,最下一篇文章中我們將會介紹如何診斷數(shù)據(jù)庫性能問題。 診斷數(shù)據(jù)庫性能問題就象醫(yī)生診斷病人病情一樣,既要結(jié)合自己積累的經(jīng)驗,又要依靠科學的診斷報告,才能準確地判斷問題的根源在哪里。前面三篇文章我們介紹了許多優(yōu)化數(shù)據(jù)庫性能的方法,固然掌握優(yōu)化技巧很重要,但診斷數(shù)據(jù)庫性能問題是優(yōu)化的前提,本文就介紹一下如何診斷數(shù)據(jù)庫性能問題。 第八步:使用SQL事件探查器和性能監(jiān)控工具有效地診斷性能問題 在SQL Server應用領(lǐng)域SQL事件探查器可能是最著名的性能故障排除工具,大多數(shù)情況下,當?shù)玫揭粋€性能問題報告后,一般首先啟動它進行診斷。 你可能已經(jīng)知道,SQL事件探查器是一個跟蹤和監(jiān)控SQL Server實例的圖形化工具,主要用于分析和衡量在數(shù)據(jù)庫服務(wù)器上執(zhí)行的TSQL性能,你可以捕捉服務(wù)器實例上的每個事件,將其保存到文件或表中供以后分析。例如,如果生產(chǎn)數(shù)據(jù)庫速度很慢,你可以使用SQL事件探查器查看哪些存儲過程執(zhí)行時耗時過多。 SQL事件探查器的基本用法 你可能已經(jīng)知道如何使用它,那么你可以跳過這一小節(jié),但我還是要重復一下,也許有許多新手閱讀本文。 1)啟動SQL事件探查器,連接到目標數(shù)據(jù)庫實例,創(chuàng)建一個新跟蹤,指定一個跟蹤模板(跟蹤模板預置了一些事件和用于跟蹤的列),如圖1所示;  圖 1 選擇跟蹤模板 2)作為可選的一步,你還可以選擇特定事件和列  圖 2 選擇跟蹤過程要捕捉的事件 3)另外你還可以點擊“組織列”按鈕,在彈出的窗口中指定列的顯示順序,點擊“列過濾器”按鈕,在彈出的窗口中設(shè)置過濾器,例如,通過設(shè)置數(shù)據(jù)庫的名稱(在like文本框中),只跟蹤特定的數(shù)據(jù)庫,如果不設(shè)置過濾器,SQL事件探查器會捕捉所有的事件,跟蹤的信息會非常多,要找出有用的關(guān)鍵信息就如大海撈針。  圖 3 過濾器設(shè)置 4)運行事件探查器,等待捕捉事件 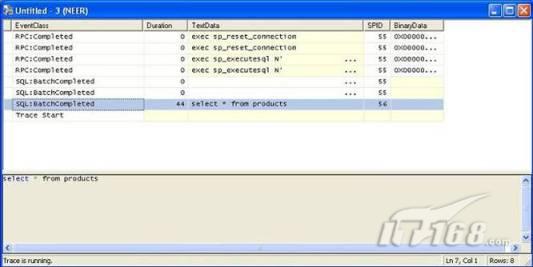 圖 4 運行事件探查器 5)跟蹤了足夠的信息后,停掉事件探查器,將跟蹤信息保存到一個文件中,或者保存到一個數(shù)據(jù)表中,如果保存到表中,需要指定表名,SQL Server會自動創(chuàng)建表中的字段。 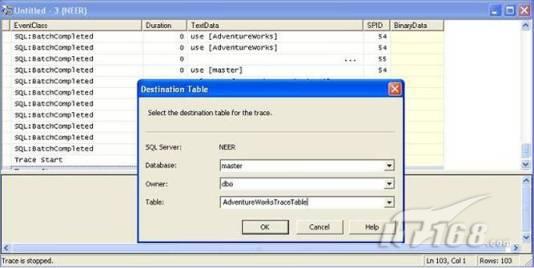 圖 5 將探查器跟蹤數(shù)據(jù)保存到表中 6)執(zhí)行下面的SQL查詢語句找出執(zhí)行代價較高的TSQL SELECT TextData,Duration,…, FROM Table_Name ORDER BY Duration DESC
圖 6 查找成本最高的TSQL/存儲過程 有效利用SQL事件探查器排除與性能相關(guān)的問題 SQL事件探查器除了可以用于找出執(zhí)行成本最高的那些TSQL或存儲過程外,還可以利用它許多強大的功能診斷和解決其它不同類型的問題。當你收到一個性能問題報告后,或者想提前診斷潛在的性能問題時都可以使用SQL事件探查器。下面是一些SQL事件探查器使用技巧,或許對你有幫助。 1)使用現(xiàn)有的模板,但需要時應創(chuàng)建你自己的模板 大多數(shù)時候現(xiàn)有的模板能夠滿足你的需求,但當診斷一個特殊類型的數(shù)據(jù)庫性能問題時(如數(shù)據(jù)庫發(fā)生死鎖),你可能需要創(chuàng)建自己的模板,在這種情況下,你可以點擊“文件”*“模板”*“新建模板”創(chuàng)建一個新模板,需要指定模板名、事件和列。當然也可以從現(xiàn)有的模板修改而來。 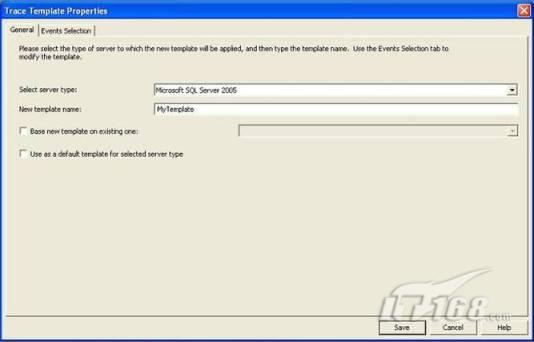 圖 7 創(chuàng)建一個新模板 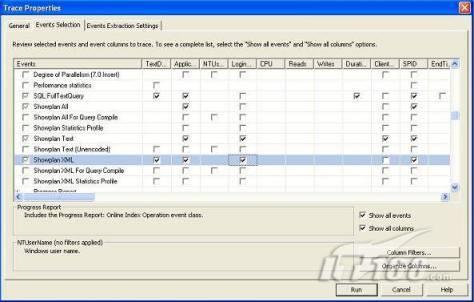 圖 8 為新模板指定事件和列 2)捕捉表掃描(TableScan)和死鎖(DeadLock)事件 沒錯,你可以使用SQL事件探查器監(jiān)聽這兩個有趣的事件。 先假設(shè)一種情況,假設(shè)你已經(jīng)在你的測試庫上創(chuàng)建了合適的索引,經(jīng)過測試后,現(xiàn)在你已經(jīng)將索引應用到生產(chǎn)服務(wù)器上了,但由于某些不明原因,生產(chǎn)數(shù)據(jù)庫的性能一直沒達到預期的那樣好,你推測執(zhí)行查詢時發(fā)生了表掃描,你希望有一種方法能夠檢測出是否真的發(fā)生了表掃描。 再假設(shè)另一種情況,假設(shè)你已經(jīng)設(shè)置好了將錯誤郵件發(fā)送到一個指定的郵件地址,這樣開發(fā)團隊可以第一時間獲得通知,并有足夠的信息進行問題診斷。某一天,你突然收到一封郵件說數(shù)據(jù)庫發(fā)生了死鎖,并在郵件中包含了數(shù)據(jù)庫級別的錯誤代碼,你需要找出是哪個TSQL創(chuàng)造了死鎖。 這時你可以打開SQL事件探查器,修改一個現(xiàn)有模板,使其可以捕捉表掃描和死鎖事件,修改好后,啟動事件探查器,運行你的應用程序,當再次發(fā)生表掃描和死鎖事件時,事件探查器就可以捕捉到,利用跟蹤信息就可以找出執(zhí)行代價最高的TSQL。 注意:從SQL Server日志文件中可能也可以找到死鎖事件記錄,在某些時候,你可能需要結(jié)合SQL Server日志和跟蹤信息才能找出引起數(shù)據(jù)庫死鎖的數(shù)據(jù)庫對象和TSQL。 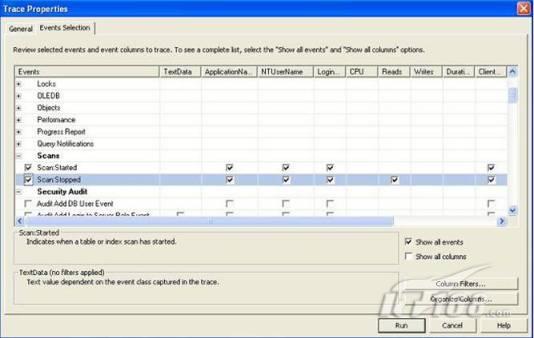 圖 9 檢測表掃描 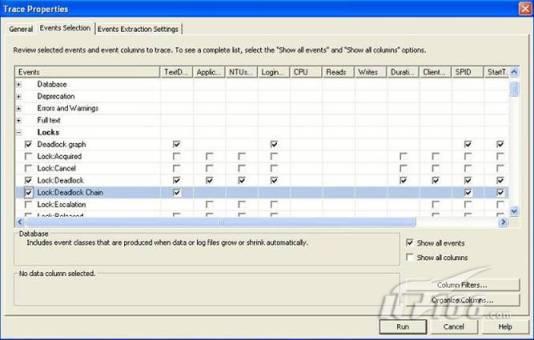 圖 10 檢測死鎖 3)創(chuàng)建重放跟蹤 某些時候,為了解決生產(chǎn)數(shù)據(jù)庫的性能問題,你需要在測試服務(wù)器上模擬一個生產(chǎn)環(huán)境,這樣可以重演性能問題。使用SQL事件探查器的TSQL_Replay模板捕捉生產(chǎn)庫上的事件,并將跟蹤信息保存為一個.trace文件,然后在測試服務(wù)器上播放跟蹤文件就可以重現(xiàn)性能問題是如何出現(xiàn)的了。 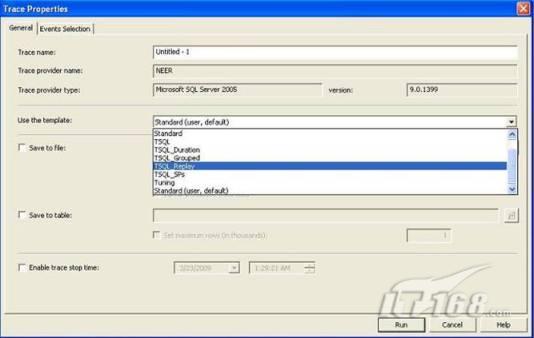 圖 11 創(chuàng)建重放跟蹤 4)創(chuàng)建優(yōu)化跟蹤 數(shù)據(jù)庫調(diào)優(yōu)顧問是一個偉大的工具,它可以給你提供很好的調(diào)優(yōu)建議,但要真正從它那獲得有用的建議,你需要模擬出與生產(chǎn)庫一樣的負載,也就是說,你需要在測試服務(wù)器上執(zhí)行相同的TSQL,打開相同數(shù)量的并發(fā)連接,然后運行調(diào)優(yōu)顧問。SQL事件探查器的Tuning模板可以捕捉到這類事件和列,使用Tuning模板運行事件探查器,捕捉跟蹤信息并保存,通過調(diào)優(yōu)顧問使用跟蹤文件在測試服務(wù)器上創(chuàng)建相同的負載。 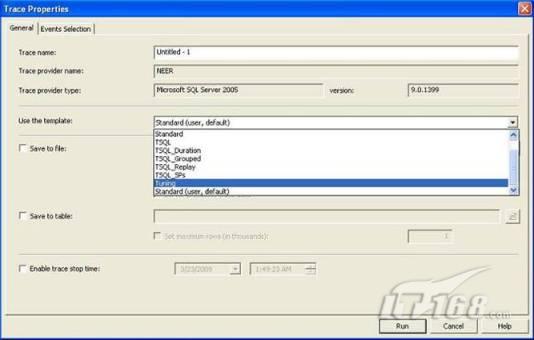 圖 12 創(chuàng)建Tuning事件探查器跟蹤 5)捕捉ShowPlan在事件探查器中包括SQL執(zhí)行計劃 有時相同的查詢在測試服務(wù)器和生產(chǎn)服務(wù)器上的性能完全不一樣,假設(shè)你遇到這種問題,你應該仔細查看一下生產(chǎn)數(shù)據(jù)庫上TSQL的執(zhí)行計劃。但問題是現(xiàn)在不能在生產(chǎn)庫上執(zhí)行這個TSQL,因為它已經(jīng)有嚴重的性能問題。這時SQL事件探查器可以派上用場,在跟蹤屬性中選中ShowPlan或ShowPlan XML,這樣可以捕捉到SQL執(zhí)行計劃和TSQL文本,然后在測試服務(wù)器上執(zhí)行相同的TSQL,并比較兩者的執(zhí)行計劃。 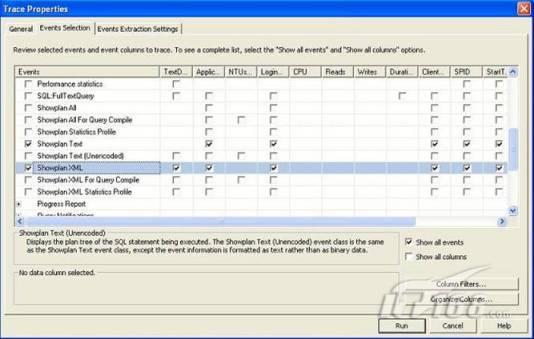 圖 13 指定捕捉執(zhí)行計劃 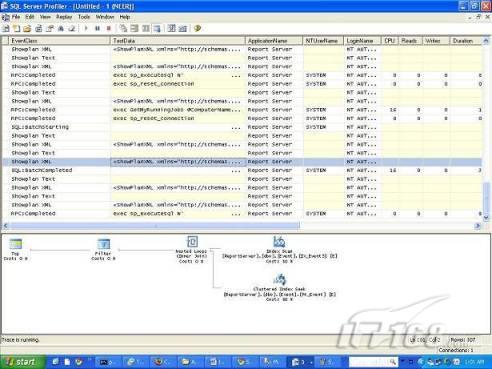 圖 14 在事件探查器跟蹤中的執(zhí)行計劃 使用性能監(jiān)視工具(PerfMon)診斷性能問題 當你的數(shù)據(jù)庫遇到性能問題時,大多數(shù)時候使用SQL事件探查器就能夠診斷和找出引起性能問題的背后原因了,但有時SQL事件探查器并不是萬能的。 例如,在生產(chǎn)庫上使用SQL事件探查器分析查詢執(zhí)行時間時,對應的TSQL執(zhí)行很慢(假設(shè)需要10秒),但同樣的TSQL在測試服務(wù)器上執(zhí)行時間卻只要200毫秒,通過分析執(zhí)行計劃和數(shù)據(jù)列,發(fā)現(xiàn)它們都沒有太大的差異,因此在生產(chǎn)庫上肯定有其它問題,那該如何揪出這些問題呢? 此時性能監(jiān)視工具(著名的PerfMon)可以幫你一把,它可以定期收集硬件和軟件相關(guān)的統(tǒng)計數(shù)據(jù),還有它是內(nèi)置于Windows操作系統(tǒng)的一個免費的工具。 當你向SQL Server數(shù)據(jù)庫發(fā)送一條TSQL語句,會產(chǎn)生許多相關(guān)的執(zhí)行參與者,包括TSQL執(zhí)行引擎,服務(wù)器緩存,SQL優(yōu)化器,輸出隊列,CPU,磁盤I/O等,只要這些參與者任何一環(huán)執(zhí)行節(jié)奏沒有跟上,最終的查詢執(zhí)行時間就會變長,使用性能監(jiān)視工具可以對這些參與者進行觀察,以找出根本原因。 使用性能監(jiān)視工具可以創(chuàng)建多個不同的性能計數(shù)器,通過圖形界面分析計數(shù)器日志,此外還可以將性能計數(shù)器日志和SQL事件探查器跟蹤信息結(jié)合起來分析。 性能監(jiān)視器基本用法介紹 Windows內(nèi)置了許多性能監(jiān)視計數(shù)器,安裝SQL Server時會添加一個SQL Server性能計數(shù)器,下面是創(chuàng)建一個性能計數(shù)器日志的過程。 1)在SQL事件探查器中啟動性能監(jiān)視工具(“工具”*“性能監(jiān)視器”); 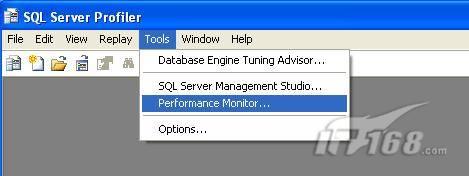 圖 15 啟動性能監(jiān)視工具 2)點擊“計數(shù)器日志”*“新建日志設(shè)置”創(chuàng)建一個新的性能計數(shù)器日志 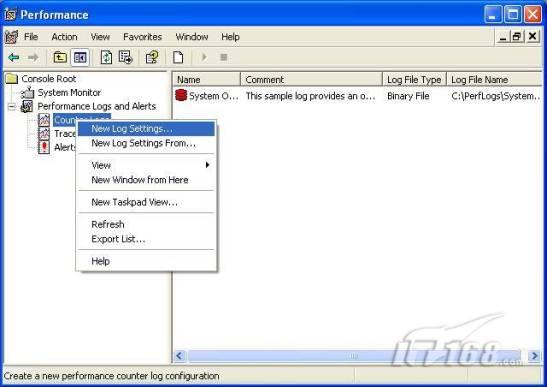 圖 16 創(chuàng)建一個性能計數(shù)器日志 指定日志文件名,點擊“確定”。 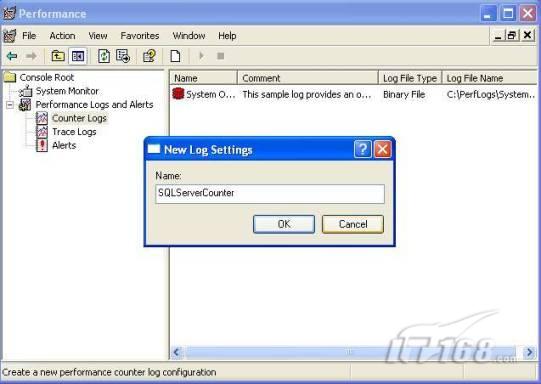 圖 17 為性能計數(shù)器日志指定名字 3)點擊“添加計數(shù)器”按鈕,選擇一個需要的計數(shù)器 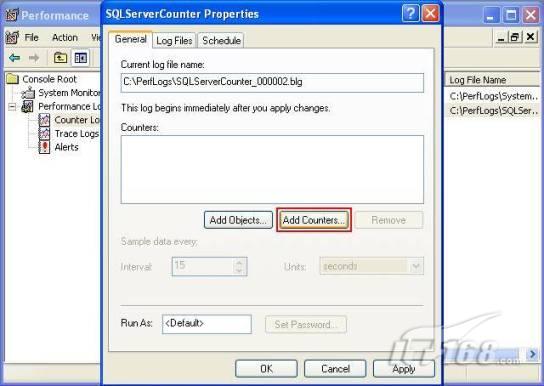 圖 18 為性能計數(shù)器日志指定計數(shù)器 4)從列表中選擇要監(jiān)視的對象和對應的計數(shù)器,點擊“關(guān)閉” 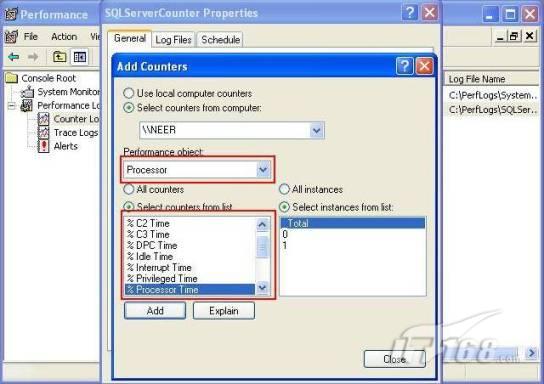 圖 19 指定對象和對應的計數(shù)器 5)選擇的計數(shù)器應顯示在窗體中 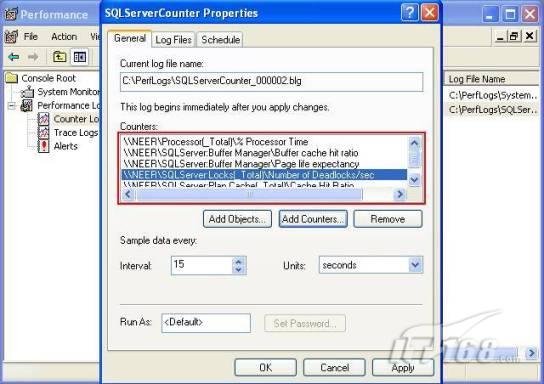 圖 20 指定計數(shù)器 6)點擊“日志文件”標簽,再點擊“配置”按鈕,指定日志文件保存位置,如果需要現(xiàn)在還可以修改日志文件名  圖 21 指定性能計數(shù)器日志文件保存位置 7)點擊“調(diào)度”標簽,指定一個時間讀取計數(shù)器性能,寫入日志文件,也可以選擇“手動”啟動和停止計數(shù)器日志。  圖 22 指定性能計數(shù)器日志運行時間 8)點擊“常規(guī)”標簽,指定收集計數(shù)器數(shù)據(jù)的間隔時間  圖 23 設(shè)置計數(shù)器間隔采樣時間 9)點擊“確定”,選擇剛剛創(chuàng)建的計數(shù)器日志,點擊右鍵啟動它。  圖 24 啟動性能計數(shù)器日志 10)為了查看日志數(shù)據(jù),再次打開性能監(jiān)視工具,點擊查看日志圖標(紅色),在“源”標簽上選中“日志文件”單選按鈕,點擊“添加”按鈕添加一個日志文件。 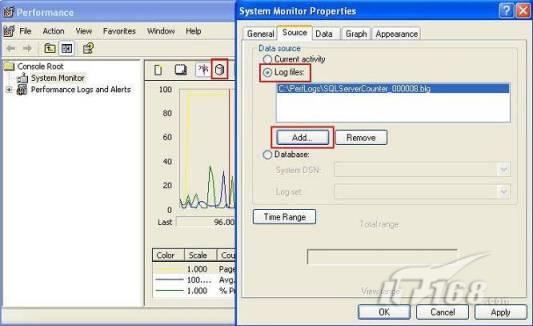 圖 25 查看性能計數(shù)器日志 11)默認情況下,在日志輸出中只有三個計數(shù)器被選中,點擊“數(shù)據(jù)”標簽可以追加其它計數(shù)器。 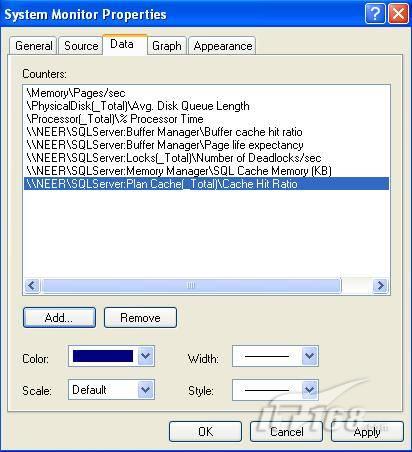 圖 26 查看日志數(shù)據(jù)時追加計數(shù)器 12)點擊“確定”,返回圖形化的性能計數(shù)器日志輸出界面 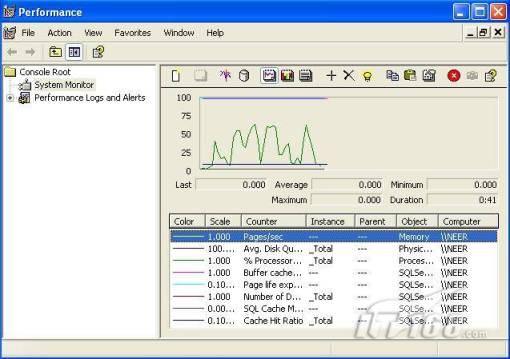 圖 27 查看性能計數(shù)器日志 關(guān)聯(lián)性能計數(shù)器日志和SQL事件探查器跟蹤信息進行深入的分析 通過SQL事件探查器可以找出哪些SQL執(zhí)行時間過長,但它卻不能給出導致執(zhí)行時間過長的上下文信息,但性能監(jiān)視工具可以提供獨立組件的性能統(tǒng)計數(shù)據(jù)(即上下文信息),它們正好互補。 如果相同的查詢在生產(chǎn)庫和測試庫上的執(zhí)行時間差別過大,那說明測試服務(wù)器的負載,環(huán)境和查詢執(zhí)行上下文都和生產(chǎn)服務(wù)器不一樣,因此需要一種方法來模擬生產(chǎn)服務(wù)器上的查詢執(zhí)行上下文,這時就需要結(jié)合SQL事件探查器的跟蹤信息和性能監(jiān)視工具的性能計數(shù)器日志。 將二者結(jié)合起來分析可以更容易找出性能問題的根本原因,例如,你可能發(fā)現(xiàn)在生產(chǎn)服務(wù)器上每次查詢都需要10秒,CPU利用率達到了100%,這時就應該放下SQL調(diào)優(yōu),先調(diào)查一下為什么CPU利用率會上升到100%。 關(guān)聯(lián)SQL事件探查器跟蹤信息和性能計數(shù)器日志的步驟如下: 1)創(chuàng)建性能計數(shù)器日志,包括下列常見的性能計數(shù)器,指定“手動”方式啟動和停止計數(shù)器日志: --網(wǎng)絡(luò)接口\輸出隊列長度 --處理器\%處理器時間 --SQL Server:緩沖管理器\緩沖區(qū)緩存命中率 --SQL Server:緩沖管理器\頁面生命周期 --SQL Server:SQL統(tǒng)計\批量請求數(shù)/秒 --SQL Server:SQL統(tǒng)計\SQL 編譯 --SQL Server:SQL統(tǒng)計\SQL 重新編譯/秒 創(chuàng)建好性能計數(shù)器日志,但不啟動它。 2)使用SQL事件探查器TSQL Duration模板創(chuàng)建一個跟蹤,添加“開始時間”和“結(jié)束時間”列跟蹤,同時啟動事件探查器跟蹤和前一步創(chuàng)建的性能計數(shù)器日志; 3)跟蹤到足夠信息后,同時停掉SQL事件探查器跟蹤和性能計數(shù)器日志,將SQL事件探查器跟蹤信息保存為一個.trc文件; 4)關(guān)閉SQL事件探查器跟蹤窗口,再使用事件探查器打開.trc文件,點擊“文件”*“導入性能數(shù)據(jù)”關(guān)聯(lián)性能計數(shù)器日志,此時會打開一個文件瀏覽器窗口,選擇剛剛保存的性能計數(shù)器日志文件進行關(guān)聯(lián); 5)在打開的窗口中選擇所有計數(shù)器,點擊“確定”,你將會看到下圖所示的界面,它同時顯示SQL事件探查器的跟蹤信息和性能計數(shù)器日志; 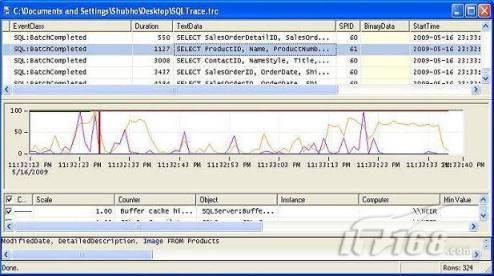 圖 28 關(guān)聯(lián)SQL事件探查器和性能監(jiān)視工具輸出 6)在事件探查器跟蹤信息輸出中選擇一條TSQL,你將會看到一個紅色豎條,這代表這條TSQL執(zhí)行時相關(guān)計數(shù)器的統(tǒng)計數(shù)據(jù)位置,同樣,點擊性能計數(shù)器日志輸出曲線中高于正常值的點,你會看到對應的TSQL在SQL事件探查器輸出中也是突出顯示的。 我相信你學會如何關(guān)聯(lián)這兩個工具的輸出數(shù)據(jù)后,一定會覺得非常方便和有趣。 小結(jié) 診斷SQL Server性能問題的工具和技術(shù)有很多,例如查看SQL Server日志文件,利用調(diào)優(yōu)顧問(DTA)獲得調(diào)優(yōu)建議,無論使用哪種工具,你都需要深入了解內(nèi)部的細節(jié)原因,只有找出最根本的原因之后,解決性能問題才會得心應手。 本系列最后一篇將介紹如何優(yōu)化數(shù)據(jù)文件和應用分區(qū)。 優(yōu)化技巧主要是面向DBA的,但我認為即使是開發(fā)人員也應該掌握這些技巧,因為不是每個開發(fā)團隊都配有專門的DBA的。 第九步:合理組織數(shù)據(jù)庫文件組和文件 創(chuàng)建SQL Server數(shù)據(jù)庫時,數(shù)據(jù)庫服務(wù)器會自動在文件系統(tǒng)上創(chuàng)建一系列的文件,之后創(chuàng)建的每一個數(shù)據(jù)庫對象實際上都是存儲在這些文件中的。SQL Server有下面三種文件: 1).mdf文件 這是最主要的數(shù)據(jù)文件,每個數(shù)據(jù)庫只能有一個主數(shù)據(jù)文件,所有系統(tǒng)對象都存儲在主數(shù)據(jù)文件中,如果不創(chuàng)建次要數(shù)據(jù)文件,所有用戶對象(用戶創(chuàng)建的數(shù)據(jù)庫對象)也都存儲在主數(shù)據(jù)文件中。 2).ndf文件 這些都是次要數(shù)據(jù)文件,它們是可選的,它們存儲的都是用戶創(chuàng)建的對象。 3).ldf文件 這些是事務(wù)日志文件,數(shù)量從一到幾個不等,它里面存儲的是事務(wù)日志。 默認情況下,創(chuàng)建SQL Server數(shù)據(jù)庫時會自動創(chuàng)建主數(shù)據(jù)文件和事務(wù)日志文件,當然也可以修改這兩個文件的屬性,如保存路徑。 文件組 為了便于管理和獲得更好的性能,數(shù)據(jù)文件通常都進行了合理的分組,創(chuàng)建一個新的SQL Server數(shù)據(jù)庫時,會自動創(chuàng)建主文件組,主數(shù)據(jù)文件就包含在主文件組中,主文件組也被設(shè)為默認組,因此所有新創(chuàng)建的用戶對象都自動存儲在主文件組中(具體說就是存儲在主數(shù)據(jù)文件中)。 如果你想將你的用戶對象(表、視圖、存儲過程和函數(shù)等)存儲在次要數(shù)據(jù)文件中,那需要: 1)創(chuàng)建一個新的文件組,并將其設(shè)為默認文件組; 2)創(chuàng)建一個新的數(shù)據(jù)文件(.ndf),將其歸于第一步創(chuàng)建的新文件組中。 以后創(chuàng)建的對象就會全部存儲在次要文件組中了。 注意:事務(wù)日志文件不屬于任何文件組。 文件/文件組組織最佳實踐 如果你的數(shù)據(jù)庫不大,那么默認的文件/文件組應該就能滿足你的需要,但如果你的數(shù)據(jù)庫變得很大時(假設(shè)有1000MB),你可以(應該)對文件/文件組進行調(diào)整以獲得更好的性能,調(diào)整文件/文件組的最佳實踐內(nèi)容如下: 1)主文件組必須完全獨立,它里面應該只存儲系統(tǒng)對象,所有的用戶對象都不應該放在主文件組中。主文件組也不應該設(shè)為默認組,將系統(tǒng)對象和用戶對象分開可以獲得更好的性能; 2)如果有多塊硬盤,可以將每個文件組中的每個文件分配到每塊硬盤上,這樣可以實現(xiàn)分布式磁盤I/O,大大提高數(shù)據(jù)讀寫速度; 3)將訪問頻繁的表及其索引放到一個單獨的文件組中,這樣讀取表數(shù)據(jù)和索引都會更快; 4)將訪問頻繁的包含Text和Image數(shù)據(jù)類型的列的表放到一個單獨的文件組中,最好將其中的Text和Image列數(shù)據(jù)放在一個獨立的硬盤中,這樣檢索該表的非Text和Image列時速度就不會受Text和Image列的影響; 5)將事務(wù)日志文件放在一個獨立的硬盤上,千萬不要和數(shù)據(jù)文件共用一塊硬盤,日志操作屬于寫密集型操作,因此保證日志寫入具有良好的I/O性能非常重要; 6)將“只讀”表單獨放到一個獨立的文件組中,同樣,將“只寫”表單獨放到一個文件組中,這樣只讀表的檢索速度會更快,只寫表的更新速度也會更快; 7)不要過度使用SQL Server的“自動增長”特性,因為自動增長的成本其實是很高的,設(shè)置“自動增長”值為一個合適的值,如一周,同樣,也不要過度頻繁地使用“自動收縮”特性,最好禁用掉自動收縮,改為手工收縮數(shù)據(jù)庫大小,或使用調(diào)度操作,設(shè)置一個合理的時間間隔,如一個月。 第十步:在大表上應用分區(qū) 什么是表分區(qū)? 表分區(qū)就是將大表拆分成多個小表,以免檢索數(shù)據(jù)時掃描的數(shù)據(jù)太多,這個思想?yún)⒖剂恕胺侄沃钡睦碚摗?/P> 當你的數(shù)據(jù)庫中有一個大表(假設(shè)有上百萬行記錄),如果其它優(yōu)化技巧都用上了,但查詢速度仍然非常慢時,你就應該考慮對這個表進行分區(qū)了。首先來看一下分區(qū)的類型: 水平分區(qū):假設(shè)有一個表包括千萬行記錄,為了便于理解,假設(shè)表有一個自動增長的主鍵字段(如id),我們可以將表拆分成10個獨立的分區(qū)表,每個分區(qū)包含100萬行記錄,分區(qū)就要依據(jù)id字段的值實施,即第一個分區(qū)包含id值從1-1000000的記錄,第二個分區(qū)包含1000001-2000000的記錄,以此類推。這種以水平方向分割表的方式就叫做水平分區(qū)。 垂直分區(qū):假設(shè)有一個表的列數(shù)和行數(shù)都非常多,其中某些列被經(jīng)常訪問,其余的列不是經(jīng)常訪問。由于表非常大,所有檢索操作都很慢,因此需要基于頻繁訪問的列進行分區(qū),這樣我們可以將這個大表拆分成多個小表,每個小表由大表的一部分列組成,這種垂直拆分表的方法就叫做垂直分區(qū)。 另一個垂直分區(qū)的原則是按有索引的列無索引列進行拆分,但這種分區(qū)法需要小心,因為如果任何查詢都涉及到檢索這兩個分區(qū),SQL引擎不得不連接這兩個分區(qū),那樣的話性能反而會低。 本文主要對水平分區(qū)做一介紹。 分區(qū)最佳實踐 1)將大表分區(qū)后,將每個分區(qū)放在一個獨立的文件中,并將這個文件存放在獨立的硬盤上,這樣數(shù)據(jù)庫引擎可以同時并行檢索多塊硬盤上的不同數(shù)據(jù)文件,提高并發(fā)讀寫速度; 2)對于歷史數(shù)據(jù),可以考慮基于歷史數(shù)據(jù)的“年齡”進行分區(qū),例如,假設(shè)表中存儲的是訂單數(shù)據(jù),可以使用訂單日期列作為分區(qū)的依據(jù),如將每年的訂單數(shù)據(jù)做成一個分區(qū)。 如何分區(qū)? 假設(shè)Order表中包含了四年(1999-2002)的訂單數(shù)據(jù),有上百萬的記錄,那如果要對這個表進行分區(qū),采取的步驟如下: 1)添加文件組 使用下面的命令創(chuàng)建一個文件組: ALTER DATABASE OrderDB ADD FILEGROUP [1999] ALTER DATABASE OrderDB ADD FILE (NAME = N'1999', FILENAME = N'C:\OrderDB\1999.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP [1999] 通過上面的語句我們添加了一個文件組1999,然后增加了一個次要數(shù)據(jù)文件“C:\OrderDB\1999.ndf”到這個文件組中。 使用上面的命令再創(chuàng)建三個文件組2000,2001和2002,每個文件組存儲一年的銷售數(shù)據(jù)。 2)創(chuàng)建分區(qū)函數(shù) 分區(qū)函數(shù)是定義分界點的一個對象,使用下面的命令創(chuàng)建分區(qū)函數(shù): CREATE PARTITION FUNCTION FNOrderDateRange (DateTime) AS RANGE LEFT FOR VALUES ('19991231', '20001231', '20011231') 上面的分區(qū)函數(shù)指定: DateTime<=1999/12/31的記錄進入第一個分區(qū); DateTime > 1999/12/31 且 <= 2000/12/31的記錄進入第二個分區(qū); DateTime > 2000/12/31 且 <= 2001/12/31的記錄進入第三個分區(qū); DateTime > 2001/12/31的記錄進入第四個分區(qū)。 RANGE LEFT指定應該進入左邊分區(qū)的邊界值,例如小于或等于1999/12/31的值都應該進入第一個分區(qū),下一個值就應該進入第二個分區(qū)了。如果使用RANGE RIGHT,邊界值以及大于邊界值的值都應該進入右邊的分區(qū),因此在這個例子中,邊界值2000/12/31就應該進入第二個分區(qū),小于這個邊界值的值就應該進入第一個分區(qū)。 3)創(chuàng)建分區(qū)方案 通過分區(qū)方案在表/索引的分區(qū)和存儲它們的文件組之間建立映射關(guān)系。創(chuàng)建分區(qū)方案的命令如下: CREATE PARTITION SCHEME OrderDatePScheme AS PARTITION FNOrderDateRange TO ([1999], [2000], [2001], [2002]) 在上面的命令中,我們指定了: 第一個分區(qū)應該進入1999文件組; 第二個分區(qū)就進入2000文件組; 第三個分區(qū)進入2001文件組; 第四個分區(qū)進入2002文件組。 4)在表上應用分區(qū) 至此,我們定義了必要的分區(qū)原則,現(xiàn)在需要做的就是給表分區(qū)了。首先使用DROP INDEX命令刪除表上現(xiàn)有的聚集索引,通常主鍵上有聚集索引,如果是刪除主鍵上的索引,還可以通過DROP CONSTRAINT刪除主鍵來間接刪除主鍵上的索引,如下面的命令刪除PK_Orders主鍵: ALTER TABLE Orders DROP CONSTRAINT PK_Orders; 在分區(qū)方案上重新創(chuàng)建聚集索引,命令如下: CREATE UNIQUE CLUSTERED INDEX PK_Orders ON Orders(OrderDate) ON OrderDatePScheme (OrderDate) 假設(shè)OrderDate列的數(shù)據(jù)在表中是唯一的,表將基于分區(qū)方案OrderDatePScheme被分區(qū),最終被分成四個小的部分,存放在四個文件組中。如果你對如何分區(qū)還有不清楚的地方,建議你去看看微軟的官方文章“SQL Server 2005中的分區(qū)表和索引”(地址:http://msdn.microsoft.com/en-us/library/ms345146%28SQL.90%29.aspx)。 第十一步:使用TSQL模板更好地管理DBMS對象(額外的一步) 為了更好地管理DBMS對象(存儲過程,函數(shù),視圖,觸發(fā)器等),需要遵循一致的結(jié)構(gòu),但由于某些原因(主要是時間限制),我們未能維護一個一致的結(jié)構(gòu),因此后來遇到性能問題或其它原因需要重新調(diào)試這些代碼時,那感覺就像是做噩夢。 為了幫助大家更好地管理DBMS對象,我創(chuàng)建了一些TSQL模板,利用這些模板你可以快速地開發(fā)出結(jié)構(gòu)一致的DBMS對象。 如果你的團隊有人專門負責檢查團隊成員編寫的TSQL代碼,在這些模板中專門有一個“審查”段落用來描寫審查意見。 我提交幾個常見的DBMS對象模板,它們是: Template_StoredProcedure.txt:存儲過程模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_StoredProcedure.txt) Template_View.txt:視圖模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_Trigger.txt) Template_Trigger.txt:觸發(fā)器模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_ScalarFunction.txt) Template_ScalarFunction.txt:標量函數(shù)模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_TableValuedFunction.txt) emplate_TableValuedFunction.txt:表值函數(shù)模板(http://www.codeproject.com/KB/database/OrganizeFilesAndPartition/Template_View.txt) 1)如何創(chuàng)建模板? 首先下載前面給出的模板代碼,然打開SQL Server管理控制臺,點擊“查看”*“模板瀏覽器”; 點擊“存儲過程”節(jié)點,點擊右鍵,在彈出的菜單中選擇“新建”*“模板”,為模板取一個易懂的名字; 在新創(chuàng)建的模板上點擊右鍵,選擇“編輯”,在彈出的窗口中輸入身份驗證信息,點擊“連接”; 連接成功后,在編輯器中打開下載的Template_StoredProcedure.txt,拷貝文件中的內(nèi)容粘貼到新建的模板中,然后點擊“保存”。 上面是創(chuàng)建一個存儲過程模板的過程,創(chuàng)建其它DBMS對象過程類似。 2)如何使用模板? 創(chuàng)建好模板后,下面就演示如何使用模板了。 首先在模板瀏覽器中,雙擊剛剛創(chuàng)建的存儲過程模板,彈出身份驗證對話框,輸入對應的身份信息,點擊“連接”; 連接成功后,模板將會在編輯器中打開,變量將會賦上適當?shù)闹? 按Ctrl+Shift+M為模板指定值,如下圖所示;
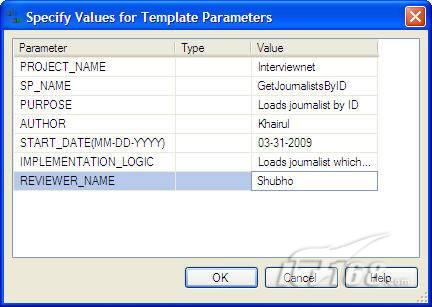
圖 1 為模板參數(shù)指定值 點擊“OK”,然后在SQL Server管理控制臺中選擇目標數(shù)據(jù)庫,然后點擊“執(zhí)行”按鈕; 如果一切順利,存儲過程就創(chuàng)建成功了。你可以根據(jù)上面的步驟創(chuàng)建其它DBMS對象。 小結(jié) 優(yōu)化講究的是一種“心態(tài)”,在優(yōu)化數(shù)據(jù)庫性能時,首先要相信性能問題總是可以解決的,然后就是結(jié)合經(jīng)驗和最佳實踐努力進行優(yōu)化,最重要的是要盡量預防性能問題的發(fā)生,在開發(fā)和部署期間,要利用一切可利用的技術(shù)和經(jīng)驗進行提前評估,千萬不要等問題出現(xiàn)了才去想辦法解決,在開發(fā)期間多花一個小時實施最佳實踐,最后可能會給你節(jié)約上百小時的故障診斷和排除時間,要學會聰明地工作,而不是辛苦地工作!
該文章在 2011/3/15 0:25:33 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")