介紹SQL在分析查詢中的排序。
DENSE_RANK()是一種高級(jí)SQL窗口函數(shù),可為結(jié)果集中的每個(gè)不同值生成一個(gè)排名,同時(shí)考慮并確保后續(xù)值獲得連續(xù)的排名。

一、了解DENSE_RANK()
與RANK()或ROW_NUMBER()等其他排序函數(shù)不同,DENSE_RANK()將具有相同值的行分配相同的排名,然后通過共享相同值的行數(shù)遞增排序。
一般的語(yǔ)法如下:
DENSE_RANK() OVER (ORDER BY column)
- ORDER BY指定用于對(duì)結(jié)果集進(jìn)行排序的列或表達(dá)式。
DENSE_RANK() OVER (PARTITION BY column ORDER BY column)
- PARTITION BY是一個(gè)可選的子句,用于根據(jù)指定的列將結(jié)果集劃分為多個(gè)分區(qū)。排序在每個(gè)分區(qū)內(nèi)分別應(yīng)用。
二、代碼示例
讓我們通過一些實(shí)際的代碼示例來說明DENSE_RANK()函數(shù)的強(qiáng)大功能:
2.1 創(chuàng)建排名
-- 首先,讓我們創(chuàng)建一個(gè)名為employees的表:
CREATE TABLE employees (
id integer,
first_name varchar(20),
last_name varchar(20),
position varchar(20),
salary varchar(20)
);
-- 讓我們向表employees中添加一些值:
INSERT INTO employees VALUES
(1, 'James', 'Flynn', 'Manager', 62000),
(2, 'Ajay', 'Ramoray', 'Manager', 62000),
(3, 'Ayse', 'Berry', 'Senior Manager', 98000),
(4, 'Gail', 'Edward', 'Associate', 50000),
(5, 'Maria', 'Frey', 'Senior Associate', 82000),
(6, 'Daniel', 'Lordman', 'Associate', 73000),
(7, 'Ferehsteh', 'Asmus', 'Senior Associate', 92000),
(8, 'Kalpana', 'Kumar', 'Manager', 86000),
(9, 'Peter', 'Ashley', 'Associate', 73000),
(10, 'Joanna', 'White', 'Senior Associate', 54000),
(11, 'Drake', 'Valley', 'Senior Associate', 54000);
-- 下面是我們的employees表的樣子
SELECT *
FROM employees;
 employees表
employees表
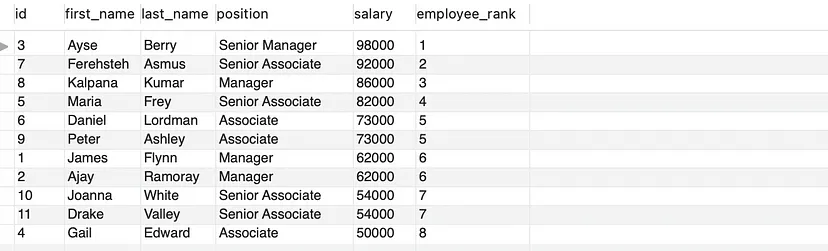
- 讓我們根據(jù)員工的薪資從高到低排列,并為薪資相同的行分配相同的排名。
SELECT * , DENSE_RANK() OVER(ORDER BY salary DESC) AS employee_rank
FROM employees;
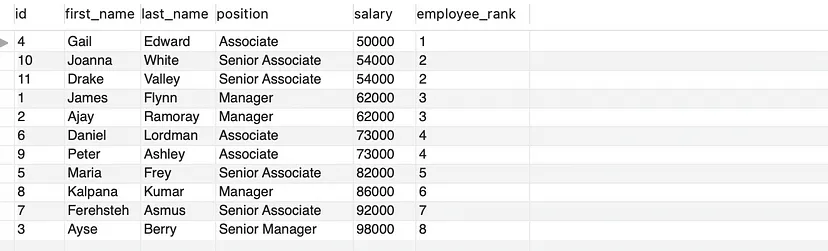
- 讓我們根據(jù)員工的薪資按從低到高排列,并為薪資相同的行分配相同的排名。
SELECT * , DENSE_RANK() OVER(ORDER BY salary) AS employee_rank
FROM employees;
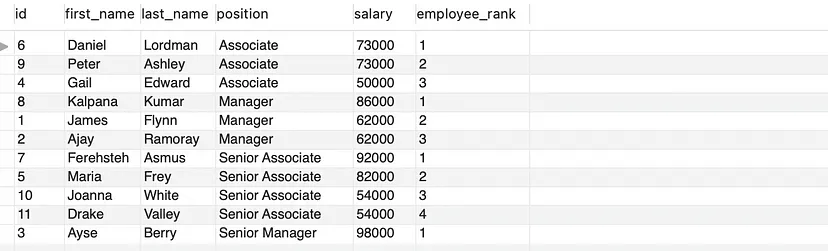
- 讓我們根據(jù)員工的薪資從高到低排序,并為薪資相同的行分配相同的排名。然后根據(jù)“職位(position)”列將結(jié)果集分成若干分區(qū)。
SELECT * , DENSE_RANK() OVER(PARTITION BY position ORDER BY salary DESC) AS employee_rank
FROM employees;
2.2 將具有相同排名的項(xiàng)目分組
當(dāng)你想要將具有相同排名的項(xiàng)目分組在一起時(shí),DENSE_RANK()非常有用。
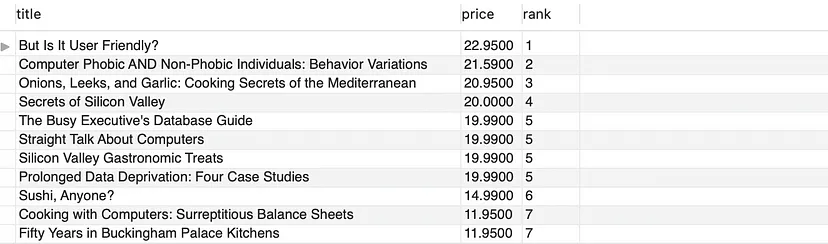
- 假設(shè)我們有一個(gè)名為“titles(標(biāo)題)”的表,其中包含“title(標(biāo)題)”和“price(價(jià)格)”列。假設(shè)我們希望按價(jià)格對(duì)書籍標(biāo)題進(jìn)行排序,并將具有相同銷售價(jià)格的書籍標(biāo)題分組:
SELECT title, price, DENSE_RANK() OVER(ORDER BY price DESC) as 'rank'
FROM titles;
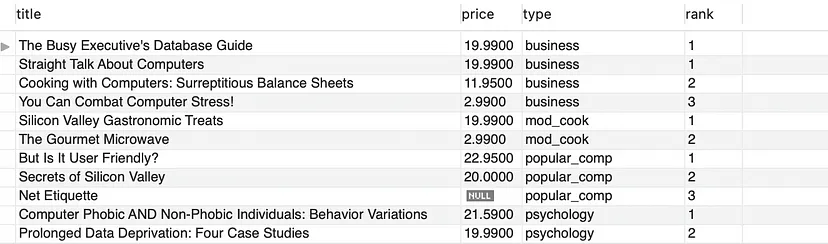
- 讓我們根據(jù)“type(類型)”列將結(jié)果集分成幾個(gè)分區(qū)。
SELECT title, price, type, DENSE_RANK() OVER(PARTITION BY type ORDER BY price DESC) as 'rank'
FROM titles;
2.3 識(shí)別最佳表現(xiàn)者
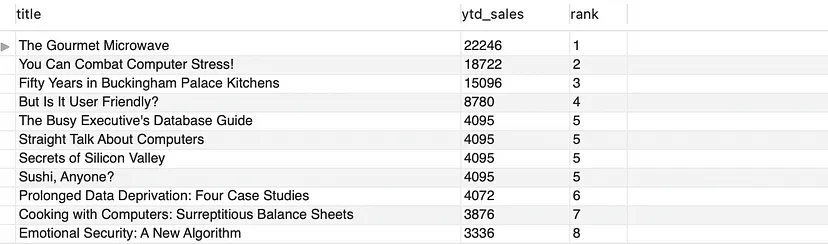
- 假設(shè)我們有一個(gè)名為“titles(標(biāo)題)”的表,其中包含“title(標(biāo)題)”和“ytd_sales”列。為了識(shí)別表現(xiàn)最佳的圖書,我們可以使用以下查詢:
SELECT title, ytd_sales, DENSE_RANK() OVER(ORDER BY ytd_sales DESC) as 'rank'
FROM titles;
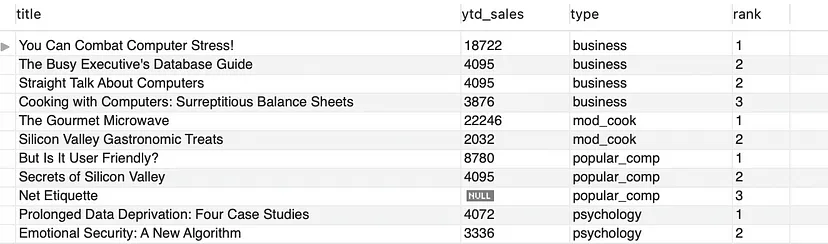
- 讓我們根據(jù)“type(類型)”列將結(jié)果集分成幾個(gè)分區(qū)。
SELECT title, ytd_sales, type, DENSE_RANK() OVER(PARTITION BY type ORDER BY ytd_sales DESC) as 'rank'
FROM titles;
三、結(jié)論
SQL中的DENSE_RANK()窗口函數(shù)功能非常強(qiáng)大,可在考慮相同值的情況下在結(jié)果集中進(jìn)行排序和分組。無(wú)論是需要?jiǎng)?chuàng)建排名、將具有相同值的項(xiàng)目進(jìn)行分組,還是需要識(shí)別表現(xiàn)最佳的項(xiàng)目,DENSE_RANK()都是首選函數(shù)。
該文章在 2024/3/30 13:19:56 編輯過
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

