高質量PDF內容提取工具PDF-Extract-Kit
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
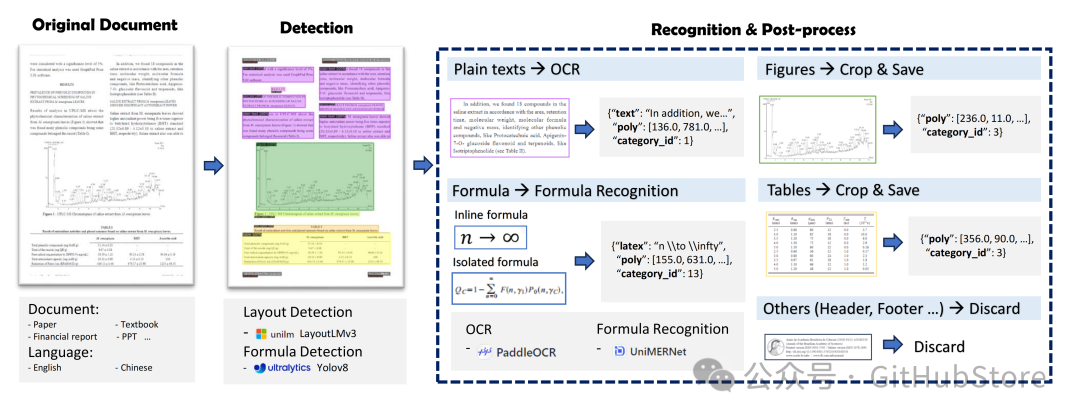
項目簡介PDF-Extract-Kit通過集成多個模型實現了PDF高質量提取,適用于學術論文、教科書、研究報告和財務報表等多種文檔類型,在掃描模糊或有水印的情況下也能保持高魯棒性 1、布局檢測采用LayoutLMv3模型進行區域檢測,包括圖像、表格、標題、文本等 2、公式檢測上采用YOLOv8,包含行內公式和行間公式 3、公式識別上采用UniMERNet識別 4、光學字符識別使用PaddleOCR進行文本識別 對于公式識別,UniMERNet可以媲美商業軟件;OCR上使用PaddleOCR,對中英文OCR效果不錯,之前分享過 PDF內容提取框架如下圖所示
結合多樣性PDF文檔標注,我們訓練了魯棒的布局檢測和公式檢測模型。在論文、教材、研報、財報等多樣性的PDF文檔上,我們的pipeline都能得到準確的提取結果,對于掃描模糊、水印等情況也有較高魯棒性。評測指標現有開源模型多基于Arxiv論文類型數據進行訓練,面對多樣性的PDF文檔,提前質量遠不能達到實用需求。相比之下,我們的模型經過多樣化數據訓練,可以適應各種類型文檔提取。 布局檢測我們與現有的開源Layout檢測模型做了對比,包括DocXchain、Surya、360LayoutAnalysis的兩個模型。而LayoutLMv3-SFT指的是我們在LayoutLMv3-base-chinese預訓練權重的基礎上進一步做了SFT訓練后的模型。論文驗證集由402張論文頁面構成,教材驗證集由587張不同來源的教材頁面構成。
公式檢測我們與開源的模型Pix2Text-MFD做了對比。另外,YOLOv8-Trained是我們在YOLOv8l模型的基礎上訓練后的權重。論文驗證集由255張論文頁面構成,多源驗證集由789張不同來源的頁面構成,包括教材、書籍等。
公式識別 公式識別我們使用的是Unimernet的權重,沒有進一步的SFT訓練,其精度驗證結果可以在其GitHub頁面獲取。 使用教程環境安裝
安裝完環境后,可能會遇到一些版本沖突導致版本變更,如果遇到了版本相關的報錯,可以嘗試下面的命令重新安裝指定版本的庫。 除了版本沖突外,可能還會遇到torch無法調用的錯誤,可以先把下面的庫卸載,然后重新安裝cuda12和cudnn。 項目鏈接
該文章在 2024/7/24 23:53:50 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


 400 186 1886
400 186 1886