Sdcb.PaddleOCR 是一個基于 PaddlePaddle 的 OCR(光學字符識別)庫,旨在提供高效的文本檢測和識別功能。它支持多種語言,并提供本地和在線模型供用戶選擇。該庫的設計使得在不同平臺(如 Windows 和 Linux)上都能方便地進行文本識別。這個比Tesseract OCR 好多了,不過要get的庫比較多。
NuGet 包
Sdcb.PaddleOCR 提供了多個 NuGet 包,用戶可以根據需要選擇合適的版本:
- Sdcb.PaddleOCR: 主要的 PaddleOCR 庫,基于 Sdcb.PaddleInference。
- Sdcb.PaddleOCR.Models.LocalV3: 包含完整的本地 V3 模型,支持多種語言(約 105MB)。
- Sdcb.PaddleOCR.Models.LocalV4: 包含完整的本地 V4 模型,支持多種語言(約 111MB)。
有關語言支持的詳細信息,請參考 PaddleOCR 模型列表。
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_en/models_list_en.md
使用方法
using OpenCvSharp;
using Sdcb.PaddleInference;
using Sdcb.PaddleInference.Native;
using Sdcb.PaddleOCR;
using Sdcb.PaddleOCR.Models.Local;
using Sdcb.PaddleOCR.Models;
namespace AppPaddlePaddle
{
internal class Program
{
static void Main(string[] args)
{
FullOcrModel model = LocalFullModels.ChineseV3;
using (PaddleOcrAll all = new PaddleOcrAll(model, PaddleDevice.Mkldnn())
{
AllowRotateDetection = true, /* 允許識別有角度的文字 */
Enable180Classification = false, /* 允許識別旋轉角度大于90度的文字 */
})
{
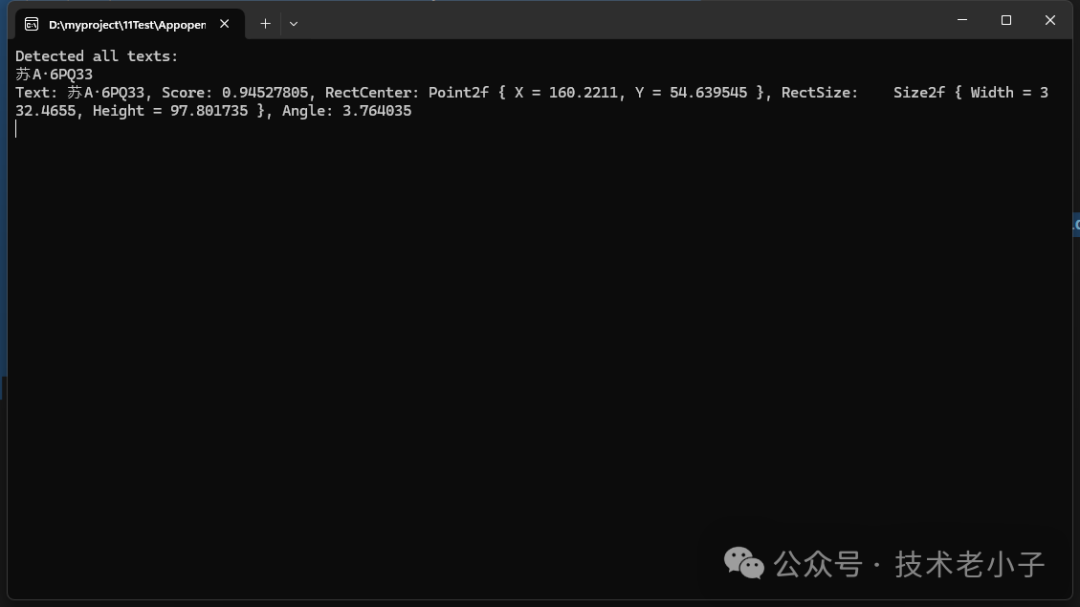
using (Mat src = Cv2.ImRead(@"temp_plate.png"))
{
PaddleOcrResult result = all.Run(src);
Console.WriteLine("Detected all texts: \n" + result.Text);
foreach (PaddleOcrResultRegion region in result.Regions)
{
Console.WriteLine($"Text: {region.Text}, Score: {region.Score}, RectCenter: {region.Rect.Center}, RectSize: {region.Rect.Size}, Angle: {region.Rect.Angle}");
}
}
}
Console.ReadKey();
}
}
}
 ?
?
性能優化
- PaddleConfig.MkldnnCacheCapacity
- PaddleOcrAll.Enable180Classification
- PaddleOcrAll.AllowRotateDetection默認值為
true,如果只處理水平文本,可以設置為 false 以提高準確性和性能。
結論
Sdcb.PaddleOCR 是一個強大的 OCR 解決方案,適用于多種平臺和語言。通過合理的配置和優化,用戶可以實現高效的文本識別,滿足不同場景的需求。
閱讀原文:原文鏈接
該文章在 2025/5/6 12:04:46 編輯過






 400 186 1886
400 186 1886


