當(dāng)我們?cè)?SQL Server 中處理大規(guī)模數(shù)據(jù)插入(INSERT)操作時(shí),往往會(huì)因?yàn)橛涗浟魁嫶蟆⑷罩緦?xiě)入多、并發(fā)競(jìng)爭(zhēng)等原因?qū)е滦阅芟陆怠?/span>TABLOCK 提示(Hint)是 SQL Server 提供的一種有效方式,可以通過(guò)減少日志記錄和允許并行加載來(lái)提升插入性能。下面,我們就來(lái)詳細(xì)討論它的原理、優(yōu)勢(shì)及使用方式,并給出一個(gè)類(lèi)似的示例供參考。
什么是 TABLOCK Hint 在執(zhí)行 INSERT、UPDATE 或 DELETE 等操作時(shí), TABLOCK 會(huì)在目標(biāo)表上獲取 表級(jí)鎖 ,并對(duì)其施加一段時(shí)間的 模式修復(fù)鎖 (Sch-M) 。這意味著在整個(gè)操作執(zhí)行期間,其他事務(wù)無(wú)法修改該表的架構(gòu)或進(jìn)行并發(fā)寫(xiě)入。雖然聽(tīng)起來(lái)會(huì)犧牲一定的并發(fā)能力,但對(duì)于一次性地批量導(dǎo)入或更新大量數(shù)據(jù)的場(chǎng)景,該鎖策略可以激活更多的優(yōu)化:
最小日志記錄 可以顯著減少日志寫(xiě)入量,尤其在批量插入時(shí)不再逐行寫(xiě)入日志,而是采用批量式記錄的方式。 并行化 在表被完全鎖定后,SQL Server 可以嘗試使用多個(gè)線程并行插入數(shù)據(jù),從而縮短整體執(zhí)行時(shí)間。 使用場(chǎng)景 一般來(lái)說(shuō), TABLOCK 適合以下場(chǎng)景:
需要一次性插入 大量數(shù)據(jù) ,并且頻繁的小批次插入不多。 能夠接受在插入過(guò)程中 暫時(shí)鎖定 目標(biāo)表(如批處理或離線數(shù)據(jù)導(dǎo)入)。 提高性能速度比表可用性更加重要的批量場(chǎng)景,例如 ETL 流程 、 數(shù)據(jù)倉(cāng)庫(kù)加載 或者 大規(guī)模臨時(shí)表作業(yè) 。 需要利用 SQL Server 并行處理能力,盡快完成數(shù)據(jù)插入。 示例:在 AdventureWorks2022 中使用 TABLOCK 以下示例展示了如何在插入數(shù)據(jù)時(shí)應(yīng)用 TABLOCK ,并與不使用 TABLOCK 的情況進(jìn)行對(duì)比。假設(shè)我們有一張目標(biāo)表 Sales.SalesOrderDetailBulk 用來(lái)存儲(chǔ)大量明細(xì)數(shù)據(jù),源表為 Sales.SalesOrderDetail 。
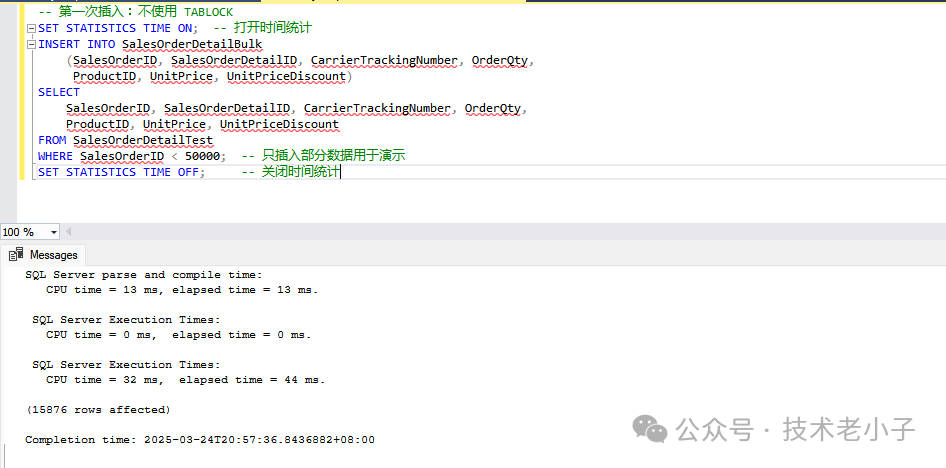
創(chuàng)建或清理目標(biāo)表 -- 如果存在測(cè)試表,先刪除 IF OBJECT_ID('SalesOrderDetailTest', 'U') IS NOT NULL DROP TABLE Sales.SalesOrderDetailTest; GO -- 創(chuàng)建測(cè)試表,模仿原始表結(jié)構(gòu) CREATE TABLE SalesOrderDetailTest ( SalesOrderID INT NOT NULL , SalesOrderDetailID INT IDENTITY ( 1 , 1 ) PRIMARY KEY , CarrierTrackingNumber NVARCHAR ( 25 ) NULL , OrderQty SMALLINT NOT NULL , ProductID INT NOT NULL , SpecialOfferID INT NOT NULL , UnitPrice MONEY NOT NULL , UnitPriceDiscount MONEY NOT NULL , LineTotal AS (OrderQty * UnitPrice * ( 1 - UnitPriceDiscount)) PERSISTED, ); GO -- 批量插入測(cè)試數(shù)據(jù)的存儲(chǔ)過(guò)程 CREATE OR ALTER PROCEDURE GenerateSalesOrderDetailTestData @NumberOfRecords INT = 100000 AS BEGIN SET NOCOUNT ON ; -- 使用公共表表達(dá)式(CTE)生成測(cè)試數(shù)據(jù) ;WITH NumberedRows AS ( SELECT TOP (@NumberOfRecords) ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL )) AS RowNum FROM sys.objects o1 CROSS JOIN sys.objects o2 ) INSERT INTO SalesOrderDetailTest ( SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount ) SELECT -- 隨機(jī)生成 SalesOrderID ABS ( CHECKSUM (NEWID()) % 50000 ) + 1 AS SalesOrderID, -- 隨機(jī)生成跟蹤號(hào) 'TRK' + RIGHT ( '00000' + CAST ( ABS ( CHECKSUM (NEWID()) % 99999 ) AS VARCHAR ( 5 )), 5 ) AS CarrierTrackingNumber, -- 隨機(jī)訂單數(shù)量 ABS ( CHECKSUM (NEWID()) % 10 ) + 1 AS OrderQty, -- 隨機(jī)產(chǎn)品ID(假設(shè)產(chǎn)品ID范圍) ABS ( CHECKSUM (NEWID()) % 1000 ) + 1 AS ProductID, -- 隨機(jī)特殊優(yōu)惠ID ABS ( CHECKSUM (NEWID()) % 10 ) + 1 AS SpecialOfferID, -- 隨機(jī)單價(jià) ROUND ( ABS ( CHECKSUM (NEWID())) % 1000 + 10.00 , 2 ) AS UnitPrice, -- 隨機(jī)折扣 ROUND ( ABS ( CHECKSUM (NEWID())) % 20 / 100.00 , 2 ) AS UnitPriceDiscount FROM NumberedRows; END GO -- 執(zhí)行存儲(chǔ)過(guò)程生成測(cè)試數(shù)據(jù) EXEC GenerateSalesOrderDetailTestData @NumberOfRecords = 500000 ; GO -- 創(chuàng)建索引以提高查詢性能 CREATE NONCLUSTERED INDEX IX_SalesOrderDetailTest_ProductID ON SalesOrderDetailTest (ProductID); CREATE NONCLUSTERED INDEX IX_SalesOrderDetailTest_SalesOrderID ON SalesOrderDetailTest (SalesOrderID); -- 如果已存在,先刪除后再創(chuàng)建 IF OBJECT_ID('SalesOrderDetailBulk', 'U') IS NOT NULL DROP TABLE SalesOrderDetailBulk; GO -- 創(chuàng)建一張用于演示的表,結(jié)構(gòu)與 Sales.SalesOrderDetail 相似 CREATE TABLE SalesOrderDetailBulk ( SalesOrderID INT , SalesOrderDetailID INT , CarrierTrackingNumber NVARCHAR ( 25 ), OrderQty SMALLINT , ProductID INT , UnitPrice MONEY, UnitPriceDiscount MONEY, LineTotal AS (OrderQty * UnitPrice) ); GO 不使用 TABLOCK 的插入操作 -- 第一次插入:不使用 TABLOCK SET STATISTICS TIME ON ; -- 打開(kāi)時(shí)間統(tǒng)計(jì) INSERT INTO SalesOrderDetailBulk (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount) SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount FROM SalesOrderDetailTest WHERE SalesOrderID < 50000 ; -- 只插入部分?jǐn)?shù)據(jù)用于演示 SET STATISTICS TIME OFF ; -- 關(guān)閉時(shí)間統(tǒng)計(jì)
觀察執(zhí)行結(jié)果,記錄 CPU 時(shí)間、總持續(xù)時(shí)間(Elapsed Time)。
帶有 TABLOCK 提示的插入 為方便比較,先清空目標(biāo)表,然后使用 TABLOCK 提示:
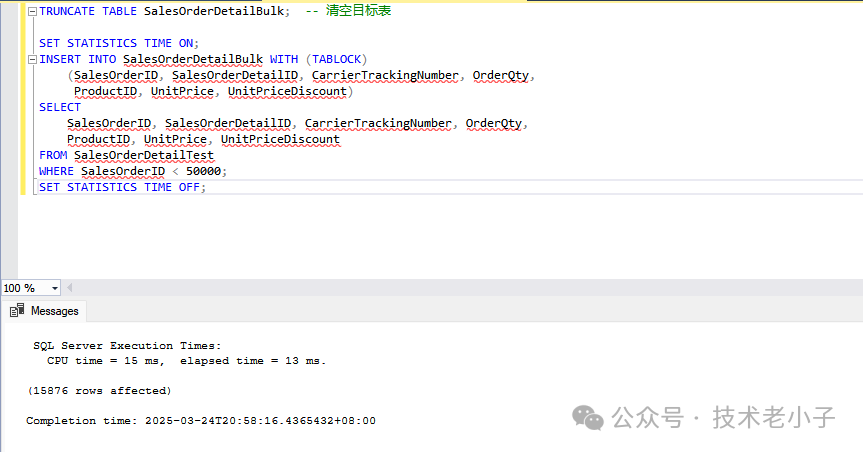
TRUNCATE TABLE SalesOrderDetailBulk; -- 清空目標(biāo)表 SET STATISTICS TIME ON ; INSERT INTO SalesOrderDetailBulk WITH (TABLOCK) (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount) SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount FROM SalesOrderDetailTest WHERE SalesOrderID < 50000 ; SET STATISTICS TIME OFF ;
因?yàn)槭褂昧吮砑?jí)鎖和最小日志記錄機(jī)制,執(zhí)行時(shí)間往往會(huì)顯著縮短,尤其在數(shù)據(jù)量更大的情況下效果更明顯。
性能對(duì)比與注意事項(xiàng) 在上面的示例中,通常會(huì)出現(xiàn)以下結(jié)論:
不使用 TABLOCK 可能耗時(shí)更長(zhǎng),SQL Server 需要更多的日志寫(xiě)入。同樣在并發(fā)場(chǎng)景下,可能有一定鎖沖突,但不會(huì)一次性全表鎖定。 使用 TABLOCK 在批量插入時(shí)速度會(huì)明顯加快,但插入期間禁止其他事務(wù)對(duì)該表進(jìn)行更新、插入或刪除,直到操作完成。 需要注意以下幾點(diǎn):
表鎖時(shí)機(jī) TABLOCK 會(huì)鎖住整個(gè)目標(biāo)表,在多用戶訪問(wèn)頻繁的線上 OLTP 系統(tǒng)中需慎用。 日志空間 雖說(shuō)最小日志記錄會(huì)減少寫(xiě)入量,但在非常龐大的插入規(guī)模下仍會(huì)對(duì)事務(wù)日志造成壓力,需確保數(shù)據(jù)庫(kù)日志文件有足夠空間。 并行插入 SQL Server 版本和數(shù)據(jù)庫(kù)兼容級(jí)別可能影響并行度,如果想發(fā)揮最大化效果,需確認(rèn)實(shí)例和查詢?cè)O(shè)置允許并行執(zhí)行。 總結(jié) TABLOCK 提示是 SQL Server 為了應(yīng)對(duì)大規(guī)模數(shù)據(jù)載入所提供的非常實(shí)用的手段之一。在臨時(shí)表操作、批量數(shù)據(jù)遷移和數(shù)據(jù)倉(cāng)庫(kù)加載等場(chǎng)景中,通過(guò) 最小化日志寫(xiě)入 和 開(kāi)啟并行插入 ,往往能成倍縮短插入時(shí)間。不過(guò),需要根據(jù)實(shí)際業(yè)務(wù)需求,綜合考慮 表鎖定 帶來(lái)的影響和可接受度,再?zèng)Q定是否使用 TABLOCK 。在合適的場(chǎng)景中合理運(yùn)用,可以為整體加載流程帶來(lái)顯著的性能提升。
閱讀原文:原文鏈接
晴ERP是一款針對(duì)中小制造業(yè)的專(zhuān)業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車(chē)隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類(lèi)企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷(xiāo)售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")


 ?
?