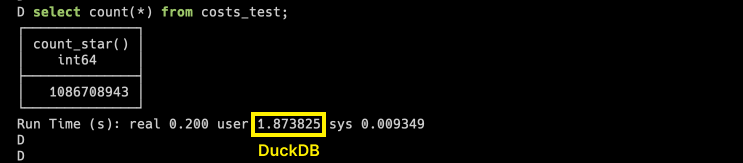
DuckDB:分析型數據庫中的SQLite,專門為解決單機數據分析性能瓶頸而生,強到離譜!
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
處理幾百萬行數據時,Pandas 慢得讓人抓狂;SQLite 遇到復雜分析查詢就卡頓;搭建傳統數據庫又太重了。 僅僅為了本地數據分析顯得殺雞用牛刀,這些痛點讓我們在數據分析的路上總是磕磕絆絆。 無獨有偶,在 GitHub 上發現了一個完美的解決方案:DuckDB。 這款被譽為 “分析型數據庫中的 SQLite” 的開源神器,專門為解決單機數據分析的性能瓶頸而生。 它以嵌入式設計為核心,將極致性能與簡單易用完美結合,讓我們能夠在本地環境中享受到前所未有的數據處理速度,徹底告別等待的焦慮。
主要功能極致性能表現:基于列式存儲和向量化執行引擎,處理超過 1 億條記錄的數據集僅需 2 秒,比 Pandas 快 350 倍以上。
零配置嵌入式設計:無需啟動服務器進程,直接嵌入到 Python、R、Java 等應用程序中,使用體驗如同 SQLite 般簡單。 豐富的數據格式支持:原生支持 CSV、Parquet、JSON 等多種格式,還能直接查詢 Pandas、Polars 數據框,真正做到"拿來即用"。 強大的 SQL 方言:支持復雜的嵌套子查詢、窗口函數、復雜類型 (數組、結構體) 等高級 SQL 特性,語法比傳統嵌入式數據庫更加豐富。 多語言生態支持:提供 Python、R、Java、C++ 等多種語言的 API,甚至還能編譯成 WebAssembly 在瀏覽器中運行。 高效的跨數據源查詢:支持直接查詢遠程文件 (S3、Azure Blob、Google Cloud Storage),實現真正的數據聯邦查詢。 安裝指南安裝 DuckDB 非常簡單,幾乎不需要任何復雜的配置過程,這也是它最大的優勢之一。 對于 Python 用戶,只需要一行命令就能完成安裝:
如果使用 conda 或 mamba 環境管理工具,也可以直接安裝:
對于 R 用戶,安裝同樣簡單:
DuckDB 的另一個優勢是它完全沒有外部依賴,整個數據庫引擎都是用 C++ 編寫的單文件實現。 這意味著安裝過程不會出現各種依賴沖突的問題,真正做到了開箱即用。 使用指南DuckDB 的使用方式非常靈活,既可以作為獨立的數據庫使用,也可以與現有的數據科學工具無縫集成。 基礎查詢操作:
文件操作:
與 Pandas 集成:
寫在最后DuckDB 作為新一代的嵌入式分析數據庫,真正解決了我們在單機數據分析中遇到的性能瓶頸問題。 無論是處理企業報表生成、數據科學實驗,還是構建輕量級的數據分析應用,DuckDB 都能提供更便捷、高效的解決方案。 它不僅讓我們告別了等待 Pandas 處理大數據的痛苦,更為我們打開了在本地環境進行高性能數據分析的全新可能性! GitHub 項目地址:https://github.com/duckdb/duckdb 閱讀原文:https://mp.weixin.qq.com/s/EkVKytDY6IJKQK2ktW7o3g 該文章在 2025/6/19 18:31:44 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886