SQL優化:使用正確的去重方法
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
上一講我們使用DISTINCT來去掉重復行以提高查詢效率,這和小伙伴們平常聽到的一條優化建議:盡量少使用DISTINCT相悖。下面我們來看看DISTINCT到底該不該使用。如果不想看處理過程的可以直接跳到紅色結論部分。 1.使用DISTINCT去掉重復數據 我們重復一下上一講的例子:
執行完之后的結果如下: 接下來,我們將這個表里的數據增大到194萬條,再重復上面的實驗。
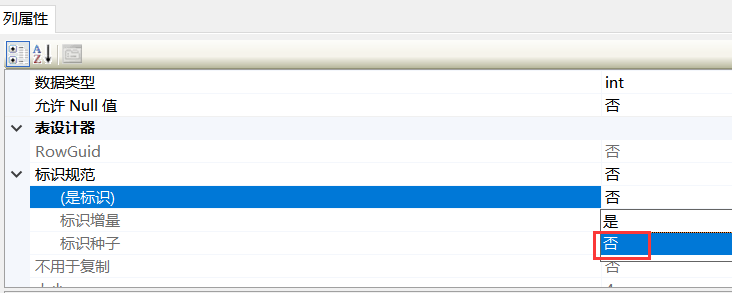
(提示:可以左右滑動代碼) 將SalesOrderDetailID的自增長屬性取消掉之后,插入1000條自身的數據,這樣我們就可以得到1000條重復的SalesOrderDetailID,相比1942072條記錄占比很小了 如下圖,將自增長標識的是換成否后即可插入了。
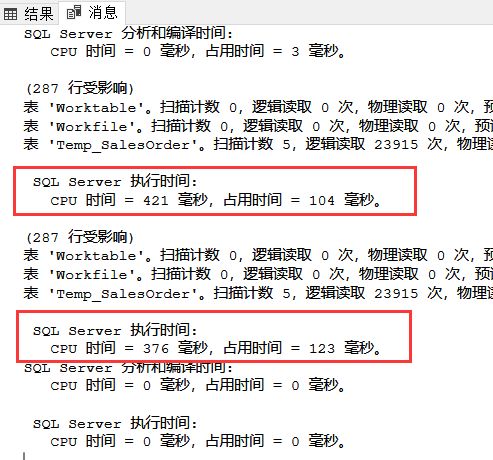
數據插入完整后,我們在將上一講的內容重復一下,看看效果如何? A.在沒建索引的情況下,我們只查詢UnitPrice這一列
我們看一下執行情況:
接下來是鑒證奇跡的時刻了,我們加DISTINCT在UnitPrice前面試試
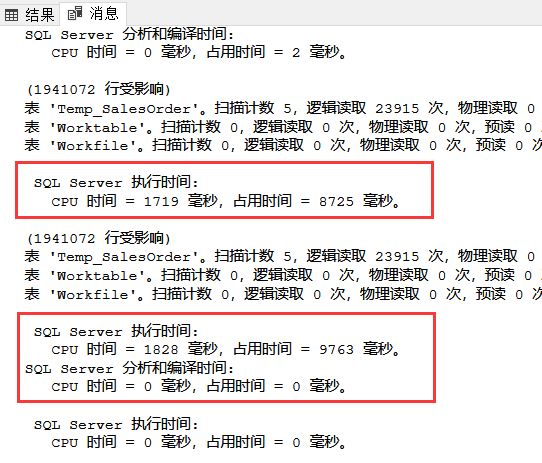
和之前的實驗結果一致,在執行時間沒有多大差別的情況下,分析時間成倍的減少了。 B.當SalesOrderDetailID取消掉自增長屬性后就和普通列一樣了。 我們來重復上面的步驟:
執行完后結果如下:
與上面的UnitPrice沒使用DISTINCT情況基本一致。 然后我們給SalesOrderDetailID加上DISTINCT后會怎么樣呢?
我們可以看到如下執行情況:
從上圖可以看到,DISTINCT已經排除了1000條記錄,但是在執行時花的時間比沒加DISTINCT更久了。 通過上述兩個實驗,我們可以得出這樣一條結論:在重復量比較高的表中,使用DISTINCT可以有效提高查詢效率,而在重復量比較低的表中,使用DISTINCT會嚴重降低查詢效率。所以并不是所有的DISTINCT都是降低效率的,當然你得提前判斷數據的重復量。 2.GROUP BY與DISTINCT去掉重復數據的對比 GROUP BY與DISTINCT類似,經常會有一些針對這兩個哪個效率高的爭議,今天我們就將這兩個在不同重復數據量的效率作下對比。 A.重復數據量多的情況下,對UnitPrice進行去重
將上述兩條語句一起執行,結果如下:
可以看出兩條語句對應的執行時間GROUP BY比DISTINCT效率高一點點。 B.重復數據量少的情況下,對SalesOrderDetailID進行去重
也是同時執行上述兩條語句,其結果如下:
作者對上述語句同時執行多次,針對重復量多的UnitPrice,GROUP BY總的處理效率比DISTINCT高一點點,但是針對重復量低的SalesOrderDetailID,DISTINCT就比GROUP BY快一點了,而如果隨著整體數據量的增加,效果會越來越明顯。 今天的課就講到這里,小伙伴可以動手嘗試一下。 閱讀原文:原文鏈接 該文章在 2025/6/23 12:56:52 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886