Puppeteer是一個Node.js庫,它提供了高級API來通過DevTools協議(Chrome DevTools Protocol https://devtools.chrome.com)控制Chrome或Chromium。 Puppeteer默認情況下無頭運行(headless)。
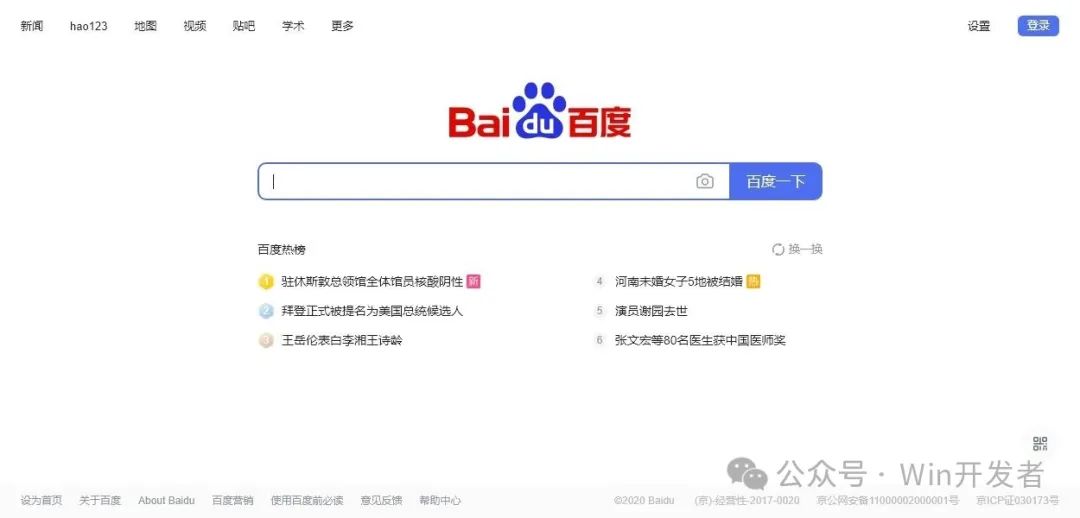
可以配置為運行完整的Chrome或Chromium,運行效果如下:
 ?
?
Puppeteer具備以下功能:
1、頁面截圖和生成PDF
2、抓取動態網頁內容
3、自動化表單提交,UI測試,鍵盤輸入等
4、測試Chrome擴展程序
Puppeteer項目地址:
https://github.com/puppeteer/puppeteer
在C#中調用,是使用了Puppeteer的移植版本,puppeteer-sharp,項目地址:
https://github.com/hardkoded/puppeteer-sharp
Puppeteer-sharp是基于.Net Standard 2.0開發,所以可以運行于NET Framework 4.6.1+、 .NET Core 2.0+的版本上.
操作系統的要求是Windows 8+或Windows Server2012+。如果需要在Windows 7上運行Puppeteer-Sharp,則可以通過設置LaunchOptions.WebSocketFactory屬性的值為System.Net.WebSockets.Client.Managed來實現。對于前端開發人員來說,Puppeteer最大的用處應該就是自動化測試,而對于爬蟲開發人員,Puppeteer最大的用處是可以很方便的抓取動態網頁。Puppeteer就等于是一個人為操作的瀏覽器,你可以控制它抓取任何動態網頁內容。
對比CEF
在前面的文章中,我使用了CEFSharp嵌入到界面中,來進行了動態頁面的抓取
使用CEFSharp獲取動態網頁源碼
使用Puppeteer也可以達到同樣的效果,但Puppeteer 用起來會更加方便, 因為它能以headless方式運行,不用顯示在界面上。而且它封裝了很多方便開發人員使用的函數。
本質 上來說,Puppeteer是通過Chrome DevTools Protocol來控制Chromium瀏覽器,而CEF提供了Chromium瀏覽器本身,它是一個Web Browser控件。
抓取動態頁面
await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true });var page = await browser.NewPageAsync();await page.GoToAsync("https://www.baidu.com");var html = await page.GetContentAsync();
網頁截圖
await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision); browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true }); var page = await browser.NewPageAsync(); await page.GoToAsync("https://www.baidu.com");
ScreenshotOptions screenshotOptions = new ScreenshotOptions(); screenshotOptions.FullPage = true; screenshotOptions.OmitBackground = false; screenshotOptions.Quality = 100; screenshotOptions.Type = ScreenshotType.Jpeg;
await page.ScreenshotAsync("D:\\a.jpg",screenshotOptions);
截圖效果如下:
保存網頁為PDF
await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision); browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true });var page = await browser.NewPageAsync(); await page.GoToAsync("https://www.baidu.com");
PdfOptions pdfOptions = new PdfOptions();pdfOptions.DisplayHeaderFooter = false; pdfOptions.FooterTemplate = ""; pdfOptions.Format = new PuppeteerSharp.Media.PaperFormat(8.27m,11.69m); pdfOptions.HeaderTemplate = ""; pdfOptions.Landscape = false; pdfOptions.MarginOptions = new PuppeteerSharp.Media.MarginOptions() { Bottom = "0px", Left = "0px", Right = "0px", Top = "0px" }; pdfOptions.Scale = 1m; await page.PdfAsync(path, pdfOptions);
保存出來的PDF效果并不怎么好,應該是文檔寬高沒控制好的原因。
重要說明:
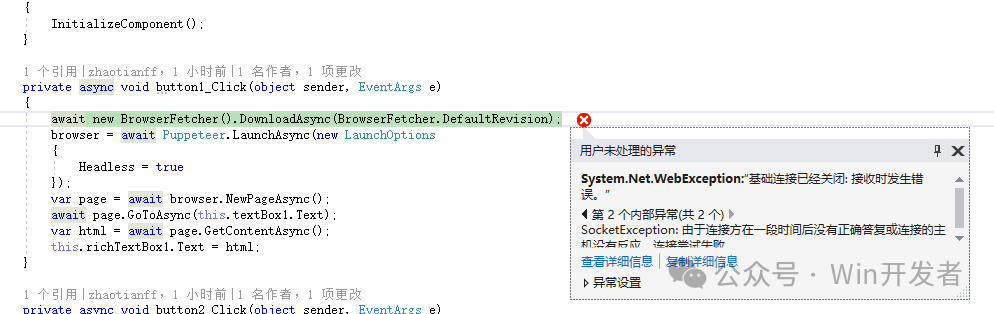
Puppeteer需要先下載Chromium瀏覽器的相關文件,也就是下面這句代碼執行的操作
await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);
可能會出現下載失敗的情況(因為需要能訪問https://storage.googleapis.com),如下圖:
可以將上面那一行代碼替換為以下代碼,配置為從華為云鏡像下載
1 2 BrowserFetcherOptions browserFetcherOptions = new BrowserFetcherOptions();3 browserFetcherOptions.Host = "https://repo.huaweicloud.com";4 await new BrowserFetcher(browserFetcherOptions).DownloadAsync(BrowserFetcher.DefaultRevision);
也可以通過以下方式(需要能訪問https://storage.googleapis.com):
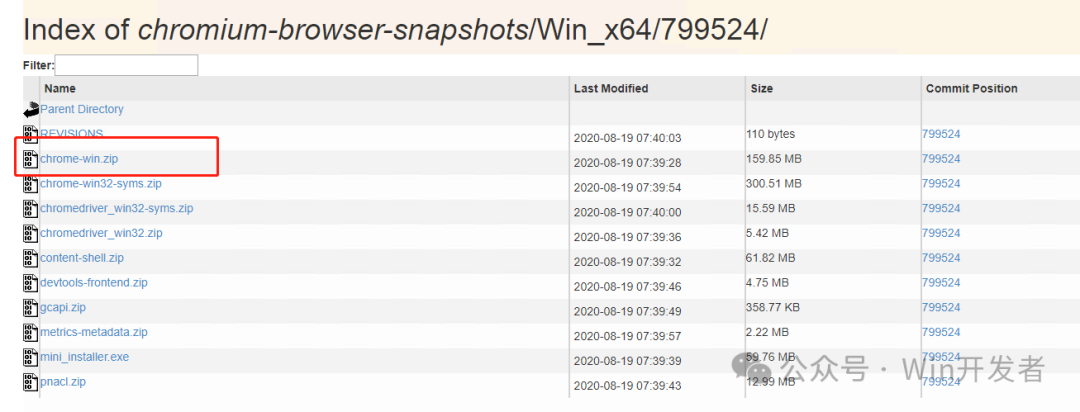
訪問google chromium開源鏡像網站,下載Chromium瀏覽器
https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/
下載后解壓到相應位置,然后通過指定Chromium路徑來進行初始化
1 LaunchOptions options = new LaunchOptions(); 2 options.Headless = true; 3 options.DefaultViewport = null; 4 5 options.IgnoreHTTPSErrors = true; 6 7 11 options.ExecutablePath = chromePath;12 13 browser = await Puppeteer.LaunchAsync(options);
本文示例代碼
https://github.com/zhaotianff/PuppeteerDemo
如果在使用過程中,遇到了問題,可以在評論區留言也可以在github提個issue給我。
更加詳細的Puppeteer使用教程以及爬蟲相關知識,可以訪問我的github
閱讀原文:原文鏈接
該文章在 2025/6/26 21:48:57 編輯過






 400 186 1886
400 186 1886